After just over three years online, Q linked to an array of YouTube videos within their posts on the chan boards. I thought it might be useful to document and analyze the URLs Q referenced over that time. Following the collection and analysis process, I compared both the URLs and the underlying content to that which Russia’s Project Lakhta operation had propagated.
As a brief refresher about the aforementioned operation, “Project Lakhta had multiple components, some involving domestic audiences within the Russian Federation and others targeting foreign audiences in various countries, including the United States.” Part of their operations included “information warfare against the United States of America.” For more information, here’s a link to the full text of the 2018 indictment that served as the source for those quotes.
Over the course of the following analysis, I’ve opted to include some information which may not be necessary for some readers. Ultimately, I lean towards providing as much information as I think might be necessary for a layperson who is generally unfamiliar with the topic(s) at hand.
During the collection process, I was primarily interested in the unique path within the linked YouTube URL. This is the portion of the URL which is assigned to individual videos that are hosted on YouTube. Without that path, YouTube has no way to ascertain which of the billions of videos a user is intending to watch. An example of a unique path for a YouTube URL which Q posted is highlighted in red below.

In the case above, everything that follows the ‘v=’ and which the ampersand symbol bookends is part of the unique path which I am most interested in. The ‘&t=119s’ found above tells YouTube to automatically start the video at 119 seconds, rather than at the start of the video. This timestamp portion of the URL could alternatively appear as ‘?t=119s’, but that would typically be found within a YouTube shortened URL (i.e., https://youtu.be/xW2ijF2ya1c?t=119s). Note that in the shortened URL, there is no ‘v=’ and the unique path starts after the third forward slash. Due to an array of YouTube link variations which cannot all be covered here, the best advice I can give is to become familiar with how the unique path is constructed, as it typically will begin to stick out like a sore thumb in the URL, given enough time.
Most of the YouTube URLs that Q posted would terminate with the unique path and would contain no ampersand symbol or question mark following the unique path. However, since this was not always the case, it was necessary to group them based on the unique path. Although I have documented the exact URL address which Q posted for future reference, I make no significant distinction between the various URL subtypes that may point to a specific video. The unique path is the key here, because this tells us exactly which video is being referenced. For example, below are three of the URL variants which Q posted for the same video. Since the unique path references the same video in each of these instances, they are all grouped together in this analysis.

Note: The space within the third URL prior to the ‘m’ is precisely how Q posted it.
Findings
Across three years of posts, Q linked to 99 unique YouTube videos. Of those, there was only one video which I was unable to properly identify the pertinent context, due to the YouTube channel operator quickly removing the video before it could be properly archived. Therefore, this video could not be included in further comparative analysis. With that in mind, we have 98 unique videos that can be analyzed.
Due to repetitive posting of some links, one or more of those 98 videos were linked in a total of 146 Q posts. For instance, one video (G2qIXXafxCQ) appeared 36 times, to include 12 times in a single Q post (#3042). All told, this video was linked in 25 unique Q posts, the most of any video. A relatively small percentage of Q posts contained more than one YouTube link in the same post. There were only six such cases, including the aforementioned post #3042. In another instance, four different YouTube links were included in the same Q post (#1941).
All that being said, we begin with a baseline of 98 unique videos and 146 unique Q posts.
In order to engage in any meaningful analysis of these videos compared to the content that was pushed by the Project Lakhta operation, we need to assess the limitations of the data. The Project Lakhta data I have available to me effectively ends after July 19, 2018. The vast majority of the previously identified Project Lakhta accounts had been suspended by this point. Moreover, there had been cycles of suspensions that had taken place before this point, with a significant number being suspended in August 2017, January 2018 and February 2018. Each round of suspensions acted to kill the stream of content that the suspended accounts would have otherwise produced. We’ll never know for certain what those accounts would have done, had they not been suspended. Of course, the suspensions were absolutely necessary. I’m certainly not arguing otherwise. However, it is important to understand that the data we have at our disposal now was increasingly affected by those rounds of suspensions. It was an unavoidable byproduct.
Now that we understand the limitations of this data, we can state that it would be statistically improbable for the Project Lakhta operation to reference content which didn’t exist yet. This would apply to any videos that were created after July 19, 2018.
If we were to compare only Q’s posts up through July 19, 2018 to the Project Lakhta operation, we find that of the 24 Q posts which contain a YouTube link, 21 of them contained content that matched Project Lakhta’s posts. This works out to 87.5%.
Of course, the above is clearly a subsample of the whole. We know the match rate will invariably drop after July 19, 2018, simply because there will be numerous instances where Q references YouTube content which preceded that date when responding to current events. There is plenty of content on YouTube to which one can refer only when it becomes relevant to recent events, breaking news, and corresponding findings. For example, in my Alice and Wonderland analysis, I referenced a handy guide on YouTube that Amazon’s Kindle Direct Publishing University had produced. Up until that analysis, I had no need to link to that content. It only became relevant in that moment because it related to contextually germane questions that were responsive to my findings.
Even though we can be certain that the match rate will drop when analyzing Q’s posts following the 19th of July, this doesn’t necessarily preclude us from analyzing some of those posts. So long as we exclude the YouTube content which simply did not exist for the Project Lakhta operation to reference, we can compare the remaining content.
Of the 146 Q posts which contained one or more YouTube links, 47 of those referred to content that only existed after July 19, 2018. This leaves 99 Q posts that can be comparatively analyzed and we’ve already analyzed 24 of them, finding an 87.5% match rate in those cases.
After checking the remaining 75 unanalyzed Q posts and comparing them to Project Lakhta’s posts, we find that 72 of the 99 matched. This comes out to 72.73%.
This is an absurdly high match rate, especially considering that Q continued posting through December 8, 2020, which was 873 days after July 19, 2018. In other words, that’s a very long time. I did not anticipate a match rate anywhere close to that percentage, especially since most of Q’s activity did not overlap with the available Project Lakhta activity. This overlapping period amounted to 265 days in total. That works out to just 25.33% of the 1046 day span in which Q was active. The 1046 figure excludes the 92 day gap in Q posts due to 8chan being taken offline. It does not exclude the shorter periods where Q arbitrarily stopped posting, since Q was not really restricted from posting during those shorter periods.
The above calculations of overlapping periods of activity are provided just to give a general idea of what that looks like and should not be used as an official measure. Those figures will only appear in the preceding paragraph and will not be used in any meaningful calculations. Moreover, someone else might consider voluntary gaps in activity to be relevant in such calculations and I don’t dispute that an argument could be made to support such a method. What’s indisputable is that Q was active far more recently than the since-suspended Project Lakhta accounts and the overlapping period was comparatively brief.
matchmaking methodology
During this analysis, I employed two methods to compare the content. The first method involved analyzing the content within the link that Q had provided. Following that analysis, I would compare it to the Project Lakhta content and determine whether the text or memes matched. There were several borderline cases which I ended up deciding against including, although I think someone else could make a compelling case about why those should have been counted as matches.
In other cases, I strongly suspect I could have ruled in their favor if only the meme, image, embedded video, or gif was included in the dataset. There are a number of instances within the dataset where the included Twitter shortened URL provides enough information for us to tell that an image, gif, or video file was part of the original tweet, but the actual file is unfortunately missing. Without being able to access and review that missing content, I would not even be able to classify them as borderline cases.
There are still other instances where the Twitter shortened URL is incomplete within the dataset. In virtually all such cases I’ve found, some portion of the ending of the URL has been chopped off. Without the entirety of the Twitter shortened URL, there is no way to ascertain what the underlying content could have been. It could have pointed to a news outlet, an image file, an embedded video, a YouTube link, or a variety of other locations online. In summary, there are a variety of limitations to what can be determined from the available data and this invariably has had an impact on this analysis. I find it reasonable to conclude that there likely would have been even more matches if not for these limitations.
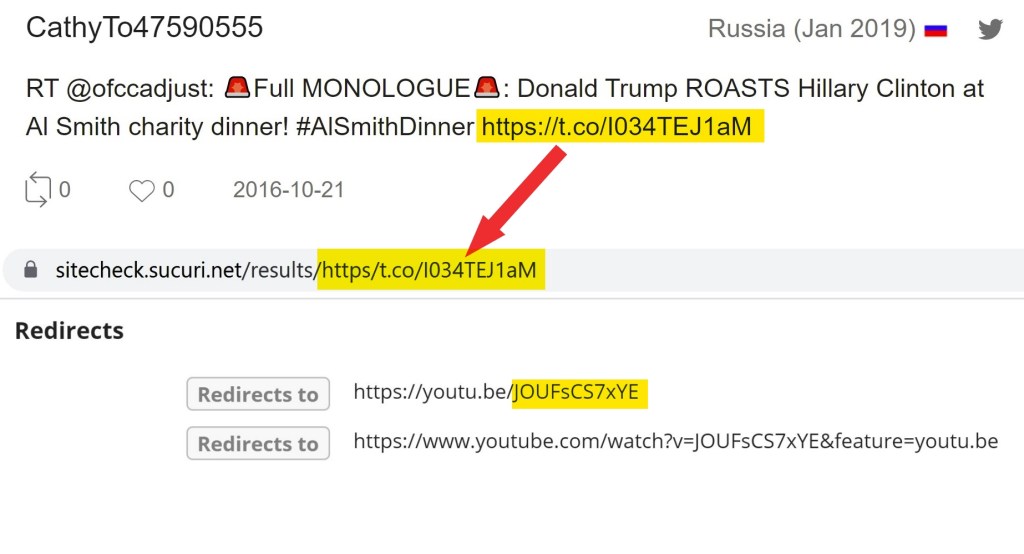
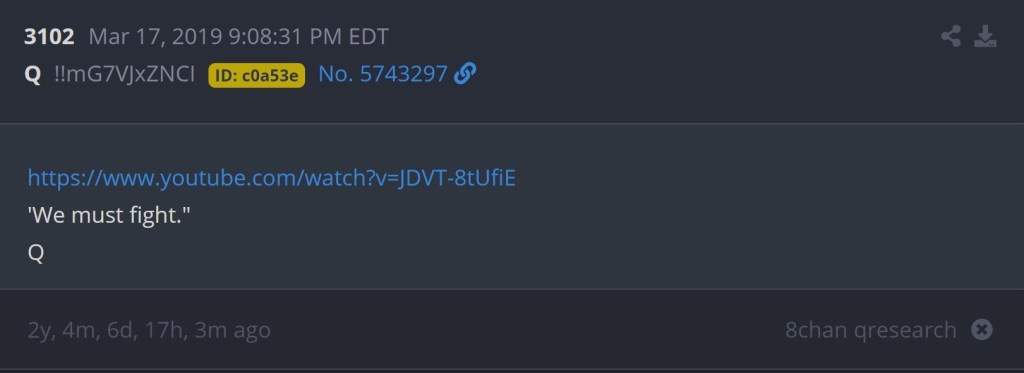
For reference, a couple examples of the matches found via the first method have been included below. Both examples will include Q’s post, the YouTube content, and the matching Project Lakhta post. The first example also showcases a cutoff URL in the Project Lakhta post. We cannot be sure where that URL would have led and cannot rule out that it could have linked to the same YouTube URL that Q posted.


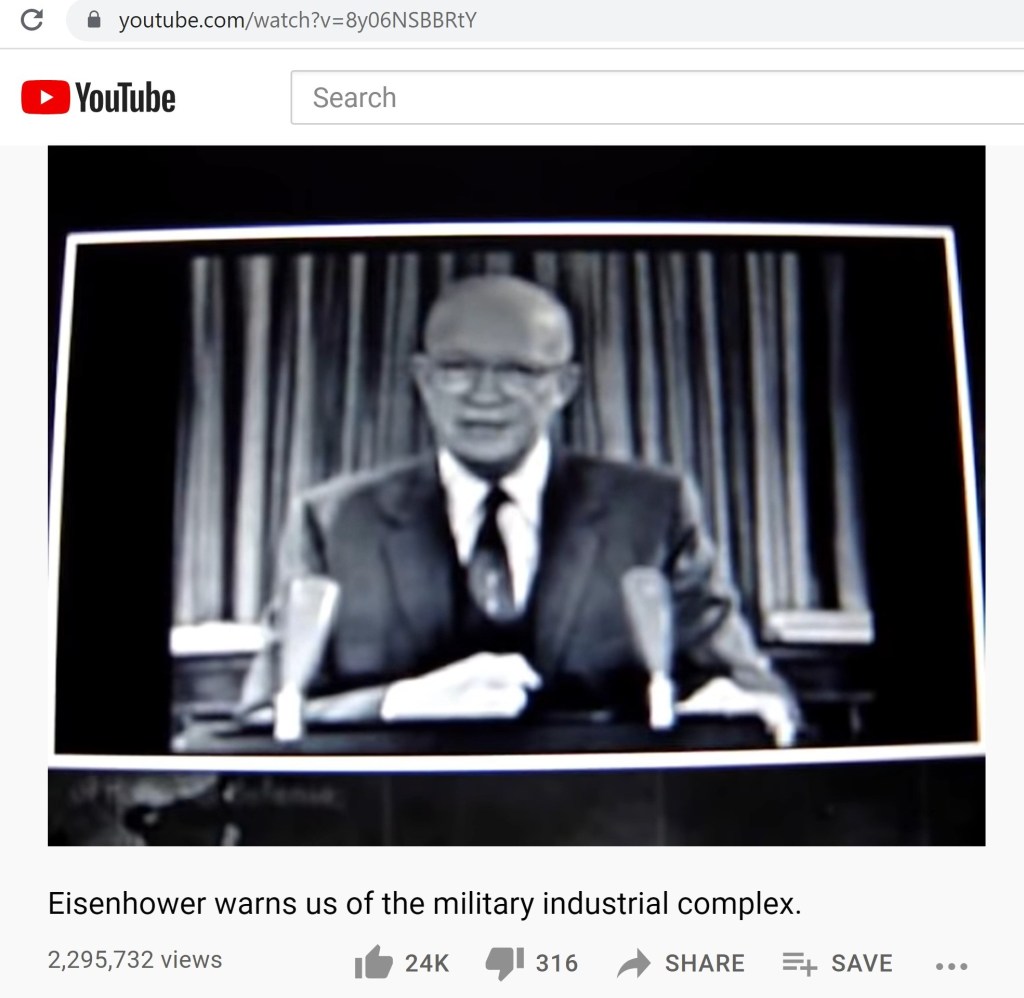


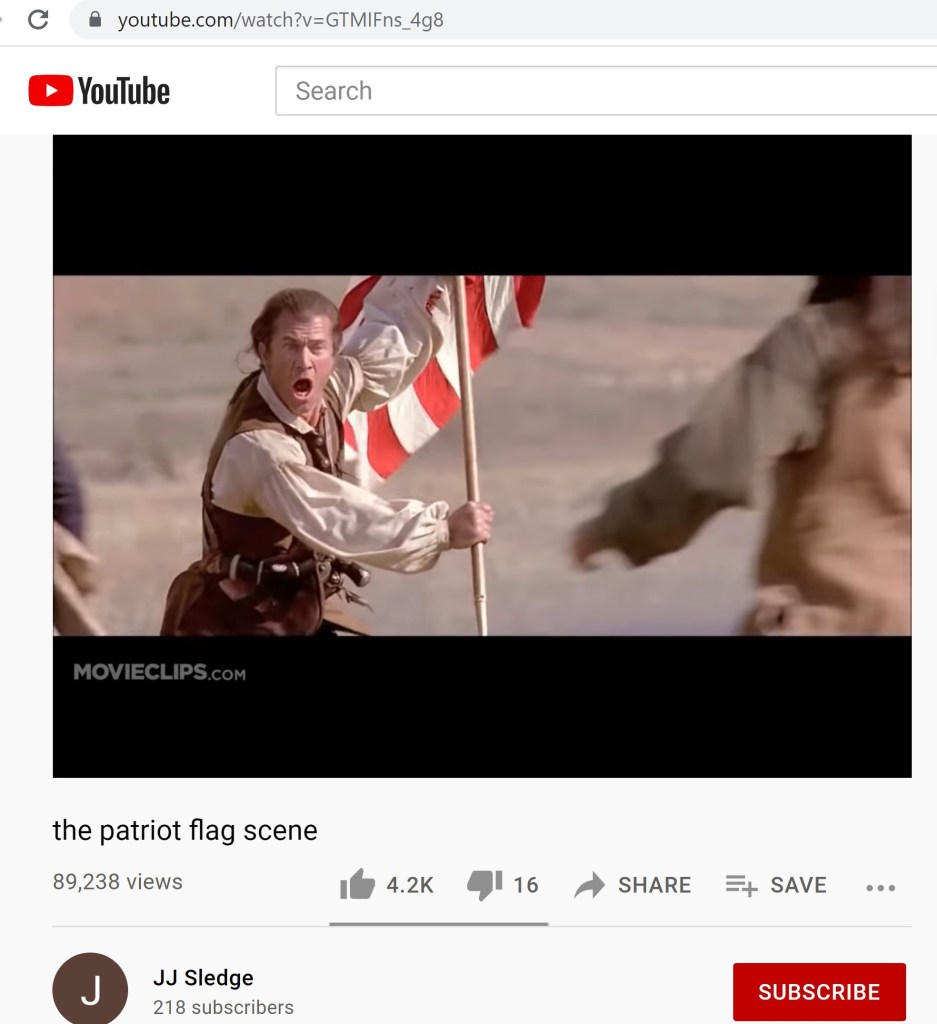
The second method was primarily in addition to the first method. In the cases where there was a linked URL within the post and that URL was fully intact, the destination was analyzed. If it matched the link that Q had posted, then this content was automatically bumped into a slightly different group. It was still a match like before, but just with a little something extra.
There were also instances where the video had been deleted or the YouTube account had been suspended. This would occasionally be an obstacle, as no functional archives of the content existed. I must note that I use the phrase functional archive here because there can be partial archives or attempted archives where the underlying content is not captured. This problem is especially prevalent with YouTube content. It will appear that there’s an archive, you’ll click it to review it and you’ll see an error message or just a black YouTube box where the video would be and none of the video details were captured in the archive. Instead of seeing the video name, the account information, the view count, etc., you’ll often find grey boxes that look like they are trying to load but never do. In some cases, there won’t even be grey boxes. Usually, all that is visible in such archives is a black rectangle with embedded YouTube controls surrounded by white. There are also instances where the video almost looks like it was fully archived but the archive will note that the underlying video was not indexed.
All that being said, there were some cases where the video was still live on YouTube or the video had been successfully archived and indexed. This allowed for a comparative analysis of the content, using the YouTube content that Q had linked to as a baseline. This method is especially useful where the Project Lakhta operation linked to a video in which the channel got suspended or the video was taken down prior to Q linking to the other YouTube video in question. Such instances could force Q to link to a mirror of that content, hosted on a channel that had yet to be suspended or where the video had not yet been removed by the user.
Update on 9/2/2021 with an example: The Project Lakhta operation, via their TEN_GOP account and their amplification network, pushed an old video from NBC and mischaracterized the contents on March 25, 2017.

The underlying video on YouTube was also published on March 25, 2017. Around two days later, known Kremlin proxy outlet Your News Wire published a similarly deceptive article which cited that video. This content continued to be recirculated at regular intervals by the Project Lakhta operation.



Sometime between November 3, 2017 and November 11, 2017, the channel which hosted that video was suspended by YouTube. The precise date of the suspension is unclear. What archive records do make clear is that the channel was still live when it was archived on November 3rd and by the next archive on the 11th of November, the record reflected that it had been “terminated due to multiple or severe violations of YouTube’s policy against spam, deceptive practices, and misleading content or other Terms of Service violations.”
Notably, the channel archive on the 3rd of November also reflected that the channel operator had a Twitter account, @VeryDicey. This account appears to have self-terminated at some point. That Twitter account was also promoted by the Project Lakhta operation.

When Q would later go on to cite the same content in October 2020, it simply would not be possible to use the same URL, due to the termination of the YouTube channel nearly 3 years prior. Interestingly, Q would cite a video that been uploaded on November 16, 2017, just a few days after the other channel had been terminated.
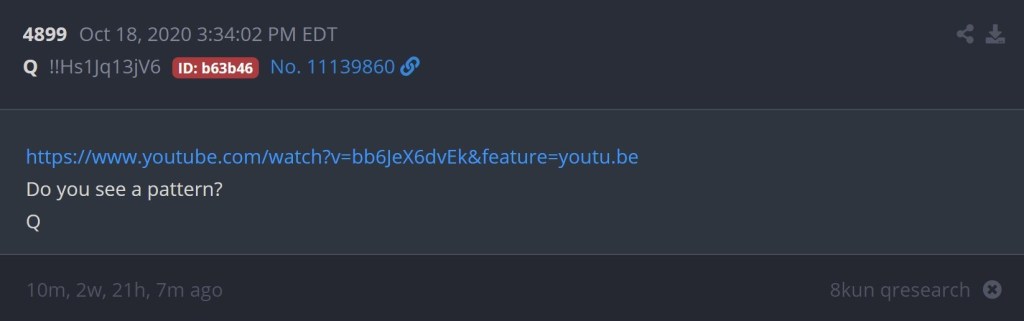
I’ve also found that the YouTube channel which Q linked to has been abandoned for over two years. On the video tab, visitors will immediately be greeted by two videos with RT (Russia Today) branding prominently displayed in the thumbnail. The channel also lists two Twitter handles (@bullshit_hero and @RobbinYoutube) that are connected to the channel. If you search for either of those handles now, Twitter will say “This account doesn’t exist.” However, as most folks who study Twitter can tell you, this message can appear when a user changes their handle, which is suspiciously the case with both these accounts. Even more suspiciously, the Project Lakhta operation promoted @bullshit_hero before the handle change.

@bullshit_hero has since changed their handle to @bullshitman_org, while @RobbinYoutube has changed their handle to @RobbinVideos. This RobbinVideos account has not tweeted since December 2018 and a review of the account activity reveals extremely basic activity, primarily consisting of retweets and tweeting links to various YouTube videos. I’m not saying the account is a bot, but it could conceivably be replaced by a bot and you wouldn’t be able to tell the difference.
The above Project Lakhta posts and subsequent Q post serve as an example where the underlying content matches but the URL doesn’t match (and could not possibly match, due to that channel termination). Below you’ll find a couple of examples of the URLs which did have a corresponding partner in the Project Lakhta data.
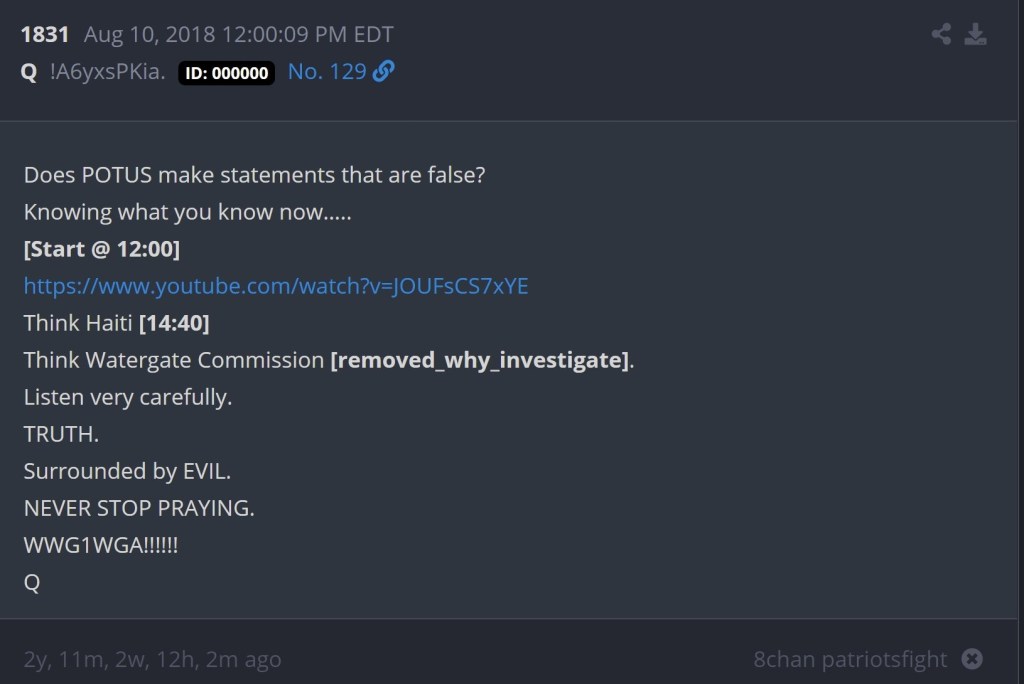

The two groups we’ve been discussing were further divided into two subgroups, giving us a total of four groups. The only difference between the first two groups and the second two groups was the timing. If Project Lakhta referenced the same content or link before Q referenced it, this would fall into one subgroup. However, if Project Lakhta referenced it on the same day or after Q referenced that material, this would fall into a separate subgroup. I would give such material a B, in the case where the content matched and a B+ where the URL matched. There were only a few instances where Project Lakhta posted said content on the same day or following the day that Q posted it, which made this a bit easier. The July 19, 2018 cutoff that we covered earlier almost certainly had some impact here.
As noted earlier, Q would post some YouTube URLs more than once. The same applies to Project Lakhta’s posts. As a result, some of Q’s links to that URL could potentially precede Project Lakhta’s and some could come afterwards. To make things simpler, I looked at whether Q or Project Lakhta was the first to link to that URL and/or reference that content. Whomever came first got all the credit, even for the select posts which came after. All or nothing.
With all of that taken into account, below is a snapshot of the pertinent results from the full analysis. To account for the fact that the video with the unique G2qIXXafxCQ path was not the sole YouTube URL within a couple Q posts, the original count of 25 total instances is listed but scratched out. Had this not been reduced by 2, it would have resulted in a double count. The chart below would have incorrectly added up to 74 total matching posts, when the accurate count is 72 matches out of 99 total unique posts.

