A curious series of events transpired in early November 2017 on 4chan, just a few days after an unusual character began luring the audience down the rabbit hole. This character, who would eventually be known as Q, started referring to a particular eBook by name early on the 5th of November. Our story begins with the events which preceded this reference.
On November 2, 2017, Q began adding “Alice & Wonderland” at the end of some 4chan posts. This first appeared in drop #47. Over the 11 posts where that appeared during the 2nd of November, Q referred to BO (Barack Obama), VJ (Valerie Jarrett), John McCain, NK (North Korea), U1 (Uranium One), Iran, Pelosi, SA (Saudi Arabia), the swamp, Sen Grassley, MW (Maxine Waters), CF (Clinton Foundation), Congress, the IRS, the United States government., Rep. Michele Bachmann, Ms. Abedin, Muslim Brotherhood, HRC (Hillary Clinton), POTUS, the MSM, various departments within the government, Twitter, Podesta’s attorney, /pol/, and the net. This is not an exhaustive list and Q even hinted at unnamed people at certain points.
On November 3, 2017, Q posted three times and referred to “Alice & Wonderland” in only one of those posts. Within that post, Q referred to “HUMA” ten times, even telling readers to “follow HUMA.”
If 4chan users were to guess who Alice was supposed to refer to, they had been provided a buffet of choices. Yet on the whole, slightly more indicators pointed towards Huma than anywhere else, since she was mentioned more than anyone else. As for “Wonderland,” various places had been mentioned thus far. One could argue that Q had remained vague enough so that “Alice & Wonderland” could be used any way Q saw fit.
All of that would change on November 4, 2017. On that day, news broke about high profile arrests of a “number of Saudi princes and former ministers.” Q noticed this news and a few hours later, Q referred to that development in a post that included the phrase “Alice & Wonderland.” This was Q’s first post on the 4th of November. A little over an hour later, Q posted the following:

Over four hours after post #74, Q stopped being vague and started being very specific regarding “Alice & Wonderland.” In multiple posts, Q wrote, “Hillary Clinton in Wonderland by Lewis Carroll” and “Saudi Arabia – the Bloody Wonderland.” Three examples are included below and the fourth (Post #84) is for later reference.
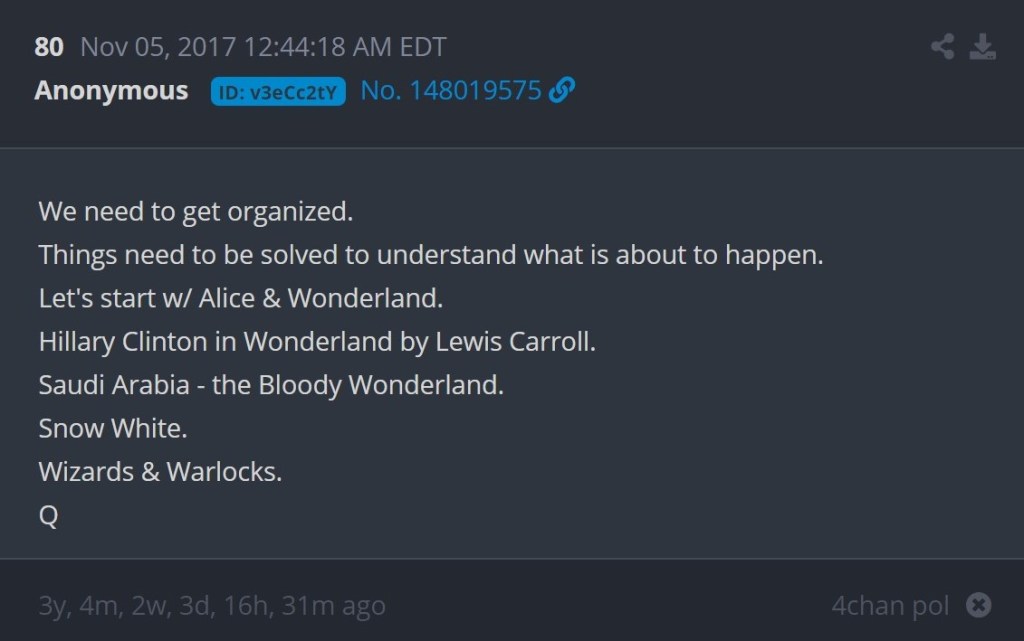
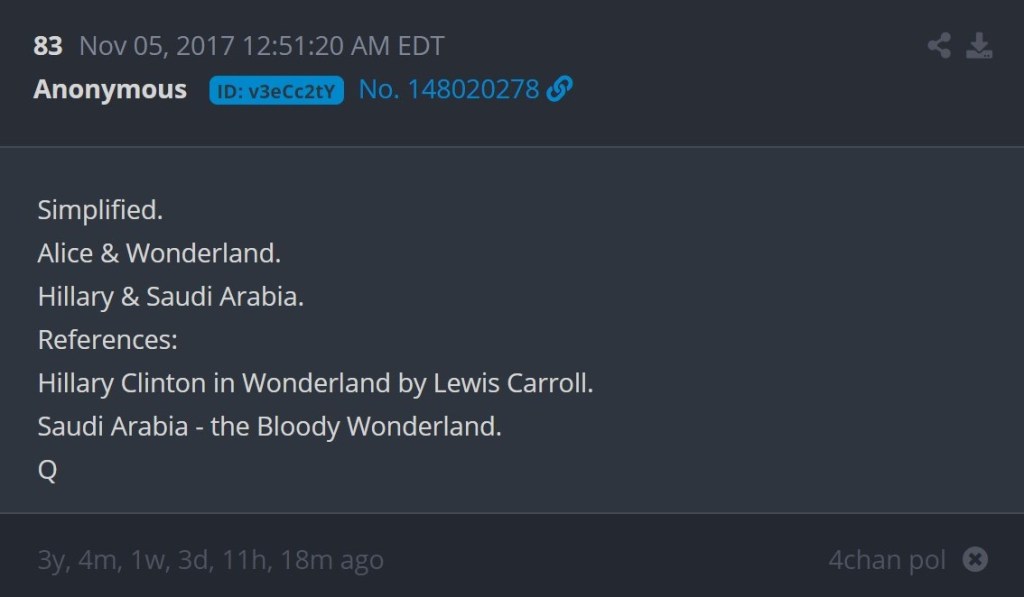
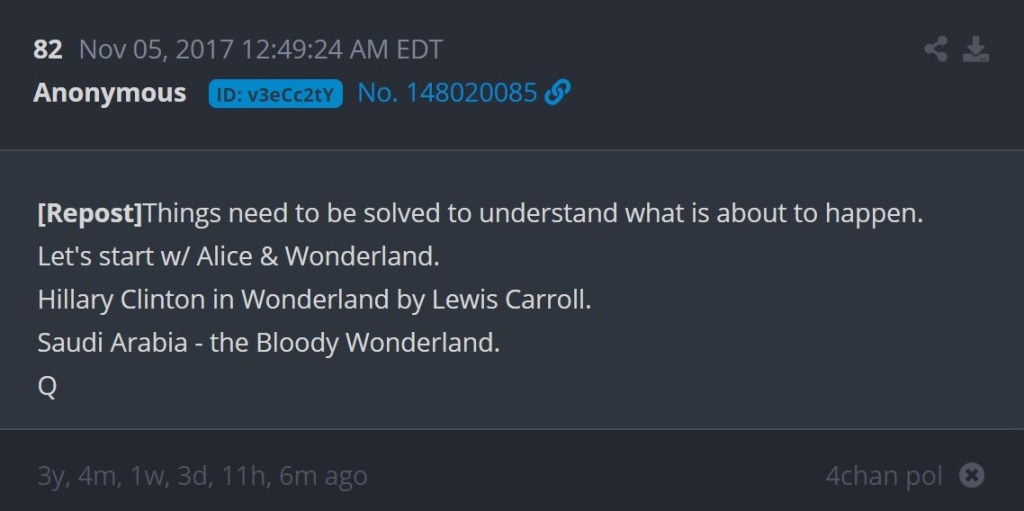
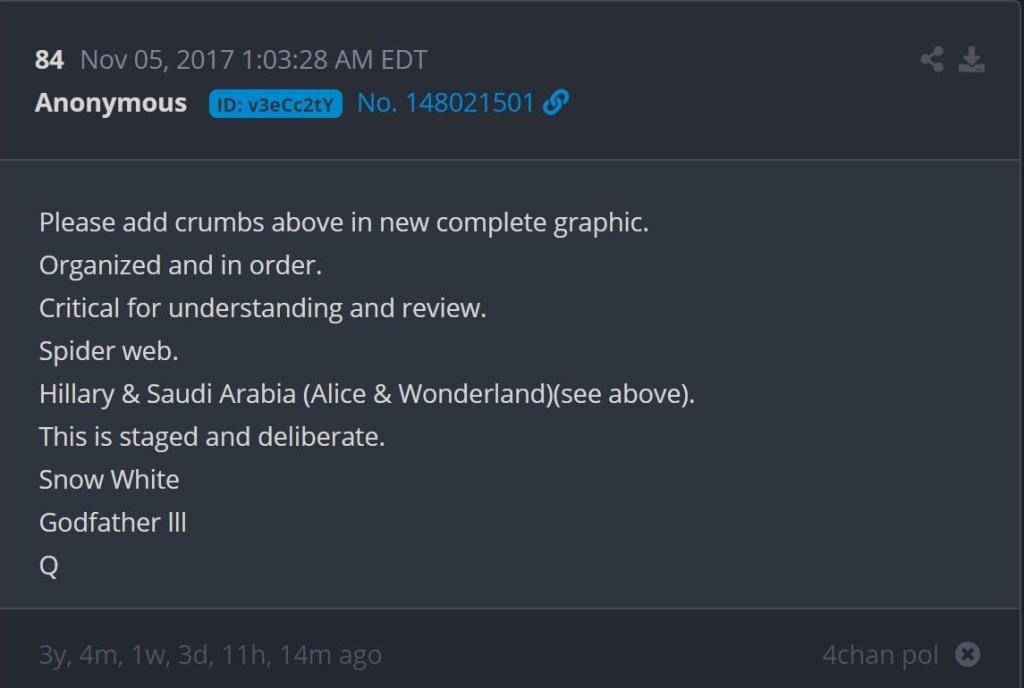
In context, first the news broke about the arrests in Saudi Arabia. Then Q stated that 4chan users would soon find out the meaning of “Alice & Wonderland.” Finally, Q got very specific in order to ‘solve’ that “Alice & Wonderland” reference. 4chan users didn’t solve anything here. Q gave out the ‘answer.’ Up until November 4, 2017, Q had arguably remained vague enough that there could have been a variety of answers. Once the arrests in Saudi Arabia happened, Q decided what “Alice & Wonderland” meant and then told 4chan users the answer. Q even wrote, “This is staged and deliberate.” This was Q, crafting a ‘QProof’ in response to current events and then spoon-feeding that ‘QProof’ to the audience. When an anonymous 4chan user (who could be anyone, including Q) posted a link to the eBook that Q had specifically mentioned, Q responded, “Finally. Correct reference.”

Before we discuss the linked eBook, let’s take a look at the second recurring reference in those aforementioned posts. In five separate posts, Q wrote “Saudi Arabia – the Bloody Wonderland.” Between those references, there was no variance whatsoever. Starting around six minutes after post #86, various posts began appearing on 4chan with the source for that exact phrase.

Within this NEO article, there is a direct mention of Lewis Carroll and a reference to Alice in Wonderland in the first sentence. This source is notable for two reasons, and I expect that many readers are already quite aware of those reasons. Firstly, it has been reported that the author “Jean Perier” only exists on paper. Second and more importantly, New Eastern Outlook is “a pseudo-academic publication of the Russian Academy of Science’s Institute of Oriental Studies that promotes disinformation and propaganda focused primarily on the Middle East, Asia, and Africa.”
This piece was republished two days later in The Fifth Column News and included a link back to the NEO article. 4chan users also linked to the URL for that republished work.
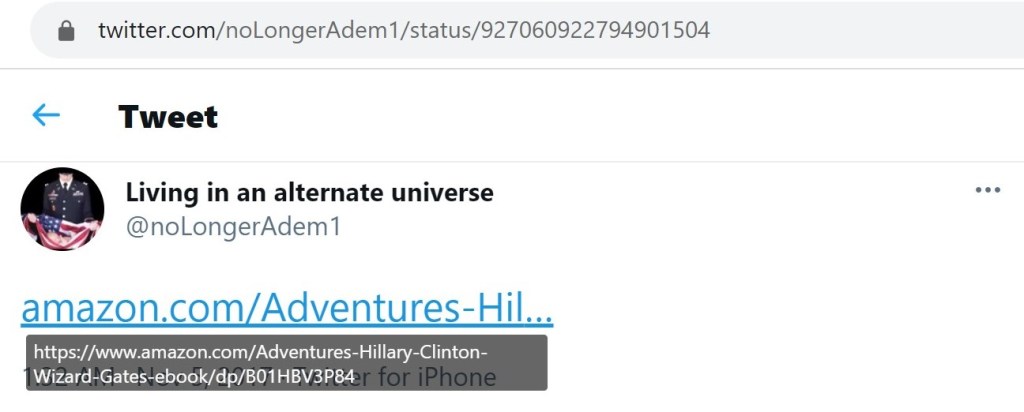
Returning to Q post #86, 4chan users received a direct confirmation that the linked eBook was a “correct reference.” As Q specified in the posts which preceded the first direct link to this eBook, the cover was indeed titled “Hillary Clinton in Wonderland” and the listed author is “Lewis Carroll.” On Amazon, visitors will find the following:

At a glance we can tell the cover image has been doctored, as the font for “Hillary Clinton” doesn’t match the existing font. This eBook arguably is a bit analogous to Q, since this persona would often take existing events and alter them to suit an agenda.
Following post #86, Q would not mention “Alice & Wonderland” again until November 12, 2017. In that instance, Q simply wrote, “Alice & Wonderland – understood.” There were only two further posts directly referencing this phrase, one on December 22, 2017 and the other on August 31, 2018. This phrase ultimately didn’t amount to much, considering how the mentions went from a flood to a trickle. Yet with some further analysis of this series of events, we can learn a bit more about Q.
This eBook has a ‘Look Inside’ option on Amazon. Upon clicking through, readers find that this is not what one might consider to be a substantive book. Rather, wherever ‘Alice’ had previously appeared in the original, ‘Hillary’ had been swapped in.

The preview acts as a bit of a refresher for those who may not recall the particulars of how Alice and Wonderland begins. It contains the first chapter and half of the second chapter, in which Hillary (Alice) follows the White Rabbit down the rabbit hole. The preview also reveals that while references to Alice have been altered, the White Rabbit has not been renamed. By comparing the chapters within the table of contents to the standard chapters, we find that four of the 12 titles contain notable alterations. The most informative alteration is of Chapter 8, which reads “Queen Winfrey’s Croquet-Ground.” This change casts Oprah Winfrey as the main villain in the story.
Within the preview, there’s a glaring and rather illuminating discrepancy. The preview claims that the eBook was published in March, 2017, while the Amazon listing on the main page reflects a publication date of June 27, 2016.


Taken by itself, this discrepancy tells us that this content was not originally on this Amazon posting. But there’s more to consider. The first review of this Amazon listing occurred on November 5, 2017. The first mention of this title on 4chan was by Q. The first mention of the ASIN (B01HOM8AV2) on 4chan came after Q directly referred to the title. Using Google or Bing, none of the results precede November 2017. Checking Twitter for references to this listing yields the same results. There are also no archives of that listing which precede this. I have found no indications that this content existed prior to Q’s references to it.
It turns out that publishers can alter virtually all aspects of their eBook listing, including the title and the manuscript itself. Amazon’s Kindle Direct Publishing University even has a handy guide on YouTube which explains this feature. This guide also explains that there are far more editing restrictions with paperback publications. These restrictions do not apply to this listing or the four other listings we will cover later.
Such alterations would make it seem like this book existed months before Q referenced it.
There are two additional red herrings found in this listing. In the earlier screenshot, there’s a reference to “New York Group Publishing.” Googling that will point people to a Ukrainian-American writer and poet named Yuriy Tarnawsky. He was one of the founding members of a writing group called New York Group and he published some writings via New York Group Publishing a few decades ago.
The other red herring is the false attribution of this publication to “The Hillary Clinton Fan Club.” There’s an obvious purpose behind such attributions, especially considering the Ukrainian tie-in via the New York Group Publishing reference. The Internet Research Agency and Russia’s media outlets were quite keen on falsely asserting that there had been collusion between Ukraine and the Clinton campaign. As the investigation into Russian interference heated up in 2017, the trolls pushed these claims in response.


Whereas most books clearly name an author, this “Hillary Clinton in Wonderland” publication and the four others we’ll cover later did not do so. In order to imply a connection to Clinton using a typical attribution, they would have needed to name an individual who the average person would know to be connected to Clinton. But that would draw questions, which would then lead to the named individual debunking that attribution. Attributing these publications to “The Hillary Clinton Fan Club” created the same impression while potentially avoiding some unwanted questions.
As I’ve documented previously, the Internet Research Agency operation had swapped Alice’s name for Clinton’s long before this.

Four additional eBooks were published by this Amazon user. Those other books can be pulled up by clicking on the hyperlinked “Hillary Clinton Fan Club” text just below the title. Doing so will direct users to this page. The four eBooks are as follows:




Now that we have all five covers available for review, there’s one rather noticeable discrepancy on all of them. A reference to “The Hillary Clinton Fan Club” is nowhere to be found. A typical author would make sure to credit themselves on the cover. However, in the case of a red herring, the creator isn’t in the mindset of a typical author, so they can miss details that the typical author certainly wouldn’t.
Within the preview pages for Trumpenstein and The Secret Garden of Hillary Clinton, we find that the creator also forgot to add the attribution to The Hillary Clinton Fan Club on the title pages. Notably, these two books were published on the 8th of November and the 9th of November, 2017, respectively. I was able to verify the validity of these dates by locating two references to the Trumpenstein eBook on 4chan, with the first mention occurring around two days after the eBook was posted. I was able to confirm the other eBook via both Twitter and 4chan.
That these publications appeared within just a few days following Q’s posts about the Hillary Clinton in Wonderland eBook does not appear to be an accident. Trumpenstein came first, naturally, since it serves to further build upon the Hillary Clinton Fan Club red herring. But since this was put together in a rush, the creator forgot that crucial attribution on the title page. I find the sole review of Trumpenstein to be both a bit funny and on the mark.

The primary point of all of this is deception. The creator can reasonably count on most people either not having the time or the inclination to scrutinize this content. As a result, it would typically pass the glance test. So long as people don’t look too closely or really think about this content, the intended effect will be achieved.
Once we ponder this content, we might note that a fan club would not be likely to rush out two publications, with the next coming out the day after the last. We’d also note that if a fan club somehow decided that doing this would be worthwhile, they would be unlikely to choose The Secret Garden for this, considering the manner in which the main character is portrayed at the start.

With so many books to choose from, this particular one would be very low on the list.
To prevent others from spending excessive time trying to sort out why there seems to be so many reviews for The Secret Garden of Hillary Clinton, we should briefly cover that. Unlike the other eBooks we have been discussing, this one has somehow managed to be included as one of many editions of the real book. There’s a button on the main page which reads “See all formats and editions.” Once pressed, several categories are revealed and each of those categories also has a button. Unfortunately, this also lumped the reviews for those various works together. After looking through the reviews for a bit, I could only conclude that it’s extraordinarily challenging to determine which particular work is being reviewed in most cases. It’s a disaster.
The next eBook required a significant alteration of the title to work in a reference to Bill Gates. Quite frankly, The Adventures of Hillary Clinton in the Land of the Wizard, Bill Gates is a real eyesore of a title. The simplest explanation for his inclusion is because he is the target of smears and conspiracies.
Using the same technique that I used to validate the publication date for Hillary Clinton in Wonderland, I found that the listed June 2016 publication date for this eBook was just as deceptive. The earliest references to this eBook came on November 5, 2017.
As for the last eBook, there’s another publication discrepancy here. The title page for Through the Looking Glass: A Hillary Clinton Adventure claims the book was published in March 2018, while the Amazon listing reflects a September 2, 2018 publication date. At first glance, there also seems to be an issue with the page numbers which appear in one section. The Amazon listing states that the eBook has 165 pages, yet in the section which precedes the preface, the listed page numbers range from page 211 to page 341. Upon closer review, this seeming discrepancy points to a potential source for the text, as these page numbers precisely match those found on Alice-in-Wonderland.net. Technically this is still a discrepancy, as these page numbers would be applicable with one of the many books which combine Alice in Wonderland and Through the Looking Glass into one publication. These page numbers are not accurate when the books are published separately, which is the case here.
Using direct links on 4chan to gauge the relative attention given to these eBooks, I find that Hillary Clinton in Wonderland is the most important, with 27 links. Next is the modified Wizard of Oz eBook, which has a total of 10 links. The final three eBooks are all relatively unimportant, with only two links apiece.
In mid-November 2017, a 4chan user posted about the four eBooks that had been published by that point. Within each of those two posts, the user linked to four Pastebin addresses. Each address contained the full text of one of the eBooks.
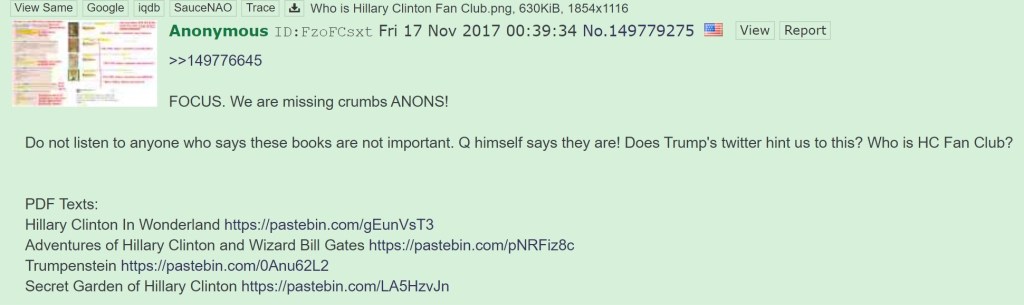
There were earlier references to some of these Pastebin links, but this was the only user to link to all four Pastebins in 2017. No one else had posted a Pastebin link to the Secret Garden of Hillary Clinton in 2017. (The fifth eBook would not be published until 2018 and I have yet to find a Pastebin link for that full text.)
By searching 4chan for each Pastebin address, we find that the first Pastebin link to be posted was for Hillary Clinton in Wonderland. Due to two discrepancies in the title page text, we can deduce that this Pastebin text likely came from the source file which was used to generate the eBook.
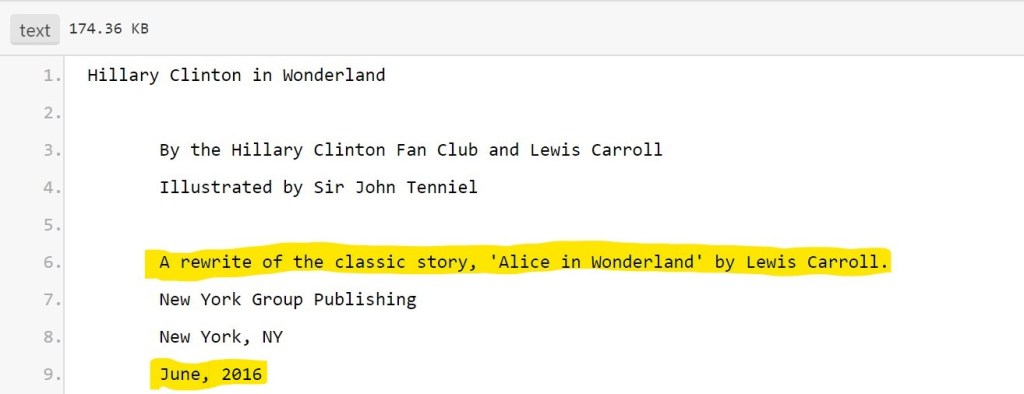
The highlighted text above could not have been extracted from the eBook, because they do not exist in the eBook. They had to have come from somewhere else. We find similarly structured text in a different eBook, namely the modified Wizard of Oz eBook. On the title page of that eBook, we find written, “A fun rewrite of the 1900 story, ‘The Wonderful Wizard of Oz’ by L. Frank Baum.”
Combined with the change to the publishing date to better match the Amazon listing, we can deduce that the creator of these eBooks made some further alterations to the Hillary Clinton in Wonderland manuscript. They may have even intended on updating the Amazon listing with this corrected manuscript, but forgot.
By searching for the Unique ID of the poster who first linked to that Pastebin address, we find that this poster was also the first 4chan user to link to the Trumpenstein eBook. As a matter of fact, it certainly seems that this user was the only one to link directly to that eBook. While the second post has a different Unique ID since it was posted in a different 4chan thread, the included screenshots are identical, as are the first ~34 words. The only difference between them is the addition of one sentence at the end of the paragraph.
Looking through the content posted under the other Unique ID, we find that this poster was trying to gin up interest in these eBooks. Three posts across both IDs stress the importance of this content. We also find that the poster linked to the modified Wizard of Oz eBook.
We also uncover direct confirmation that both these Unique IDs belong to the same individual. Another 4chan user replied to a post from Unique ID +/WdMQHN. This prompted the following response via the other ID, +JqgosM5.

Across these two IDs, we also find a carefully orchestrated bit of deception. To paraphrase, this user insisted there were crumbs to be found within these eBooks. Some 4chan users were essentially complaining about the idea of paying for these eBooks to look for crumbs. This user then claimed to have already purchased these books days ago and asks, “Should I pastebin them?” After acknowledging that one cannot simply copy paste from an eBook (see above), some users provided suggestions on how to convert an eBook. This user replied, “On it! Standby.” A little over an hour later, this user posted the Pastebin link to Hillary Clinton in Wonderland while replying to a couple users.
The implication here is that this poster used one of the suggested methods to convert the eBook and then created a Pastebin with the extracted text. But we know that is not what happened, since the text did not precisely match the eBook’s contents. This was staged and deliberate, to borrow a phrase. Based on word choice, it is likely that this poster was behind all of the Pastebins, since the poster wrote, “Should I pastebin them?” (emphasis added).
As we covered earlier, an anon posted links to all four Pastebin addresses on the 17th of November. Those posts were the first time that the Pastebin for the Secret Garden of Hillary Clinton was linked on 4chan. Due to word usage and other indicators, we can surmise that this is the same anon we’ve been discussing. These posts stated that “We’re/We are missing crumbs” and emphasized the importance of these eBooks. The included screenshots were again identical to each other in the two posts on the 17th of November. Both were also the first to link to the respective Pastebin addresses. Furthermore, in both instances, the user replied to sequential CBTS (Calm Before The Storm) threads on 4chan. On the 10th of November, the user replied to CBTS thread #196 and #197. On the 17th of November, the user replied to CBTS thread #389 and #390.
Twitter user @QOrigins has been reviewing 4chan posts and documenting various aspects of Q’s Origins. Along the way, this user has found and written about sock puppet accounts that were highly likely to have been operated by Q. In consideration of the evidence we’ve covered regarding the publication and promotion of these eBooks, it is quite likely that this is another case of sock puppetry by Q. However, there is a small chance that the Amazon publications and the anonymous 4chan posts were produced by an accomplice of Q. In either case, some rather clever sleight of hand was incorporated with the aim of tricking the audience.
What Happens On 4chan Doesn’t Always Stay On 4chan
As long as a user opts to post anonymously on 4chan, the site’s design makes it easier for that user to obscure their cumulative activity on the site. There is no registration or login requirement on the site, so anyone from nearly anywhere can post. Unique IDs on 4chan can provide some visibility into the actions of a particular poster within a specific thread, but even Unique IDs can be circumvented by knowledgeable users.
However, what happens on 4chan doesn’t always stay on 4chan. Some 4chan users are active on other social media platforms. For instance, Q would frequently post about Twitter on 4chan/8chan/8kun. Moreover, within some Twitter screenshots that Q posted, we find that the ‘like’ icon had been clicked. While Q could have been reposting some other 4chan users’ screenshots, there’s a reasonable chance that Q had at least one account on Twitter.
Once content that appeared on 4chan starts showing up on Twitter, we can get a better sense of the kinds of users that are spreading the content in question. After a bit of searching, I’ve found that links to the Amazon listing for four of the five eBooks also appeared on Twitter. In the case of two eBooks, the listings were only linked to once. In fact, the same three eBooks which received very limited attention on 4chan were either linked to only once or not at all on Twitter. The only links to get significant attention were to the modified Wizard of Oz and the Hillary Clinton in Wonderland eBooks. This is in keeping with our earlier findings about these eBooks on 4chan.
By now, you likely will not be surprised to learn that Hillary Clinton fans were not the ones linking to these eBooks on Twitter. None of the evidence I’ve found online substantiates that Hillary Clinton fans were involved in the creation or promotion of these eBooks, despite what the red herring on Amazon tried to suggest.
The evidence I’ve uncovered on Twitter reveals something else entirely. The four eBooks were each promoted by Kremlin supporters.
Statistically, the odds of this occurring by chance are very low. The Russian population only accounted for 1.92% of the world population in 2017. As recent protests in Russia show, not every Russian is pro-Kremlin. Some Russians are openly opposed to the Kremlin. Accordingly, the percentage of openly pro-Kremlin people in the world is likely far lower than that 1.92% figure. Therefore, the odds that a pro-Kremlin Twitter user promoted even one of those eBook links by chance is quite low, especially since these links did not proliferate widely. Over the remainder of this study, I will be reviewing the activity of four of those users.
@HappyGoddesS
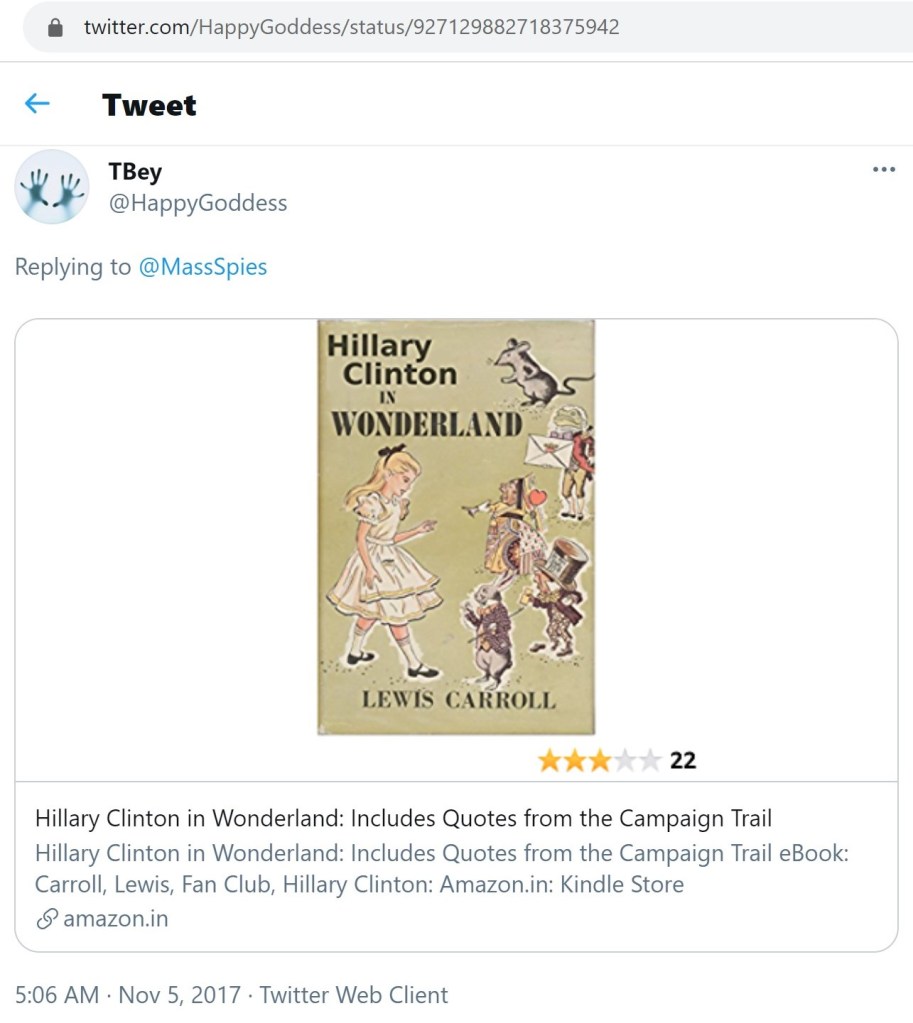
The above tweet was sent a few hours after Q referenced that eBook on November 5, 2017. The Twitter user was a QAnon promoter, as were the others which will follow. Up until mid-August 2020, this user had QAnon hashtags in their Twitter bio, according to archives. All four accounts we’ll be covering here had QAnon messaging and/or imagery within their profiles. Three of the four have removed that messaging and/or imagery, in keeping with Q’s posts which recommended that users drop direct references to Q and QAnon to circumvent Twitter’s moderation of QAnon.
@HappyGoddess didn’t solely tweet links to QAnon posts and content. As seen below, this operator also linked to the Duginist outlet geopolitica.ru. The idea being propagated within that article title has been echoed by Q, albeit not quite so overtly.

This account also spread content from Fort Russ News, Russia Today (RT), Sputnik News, and the Strategic Culture Foundation, among other sites. These sites are part of Russia’s disinformation and propaganda ecosystem, which includes the site we covered earlier, New Eastern Outlook.

The final linked outlet, Russia Insider, is not listed within that ecosystem documentation I referenced earlier. However, this outlet operates out of Moscow, spreads Russian state propaganda, and has sought funding from Russian oligarchs who are close to the Kremlin. Whether that funding was ever provided still remains undisclosed.
@HappyGoddess also promoted Putin, beyond what we reviewed earlier.
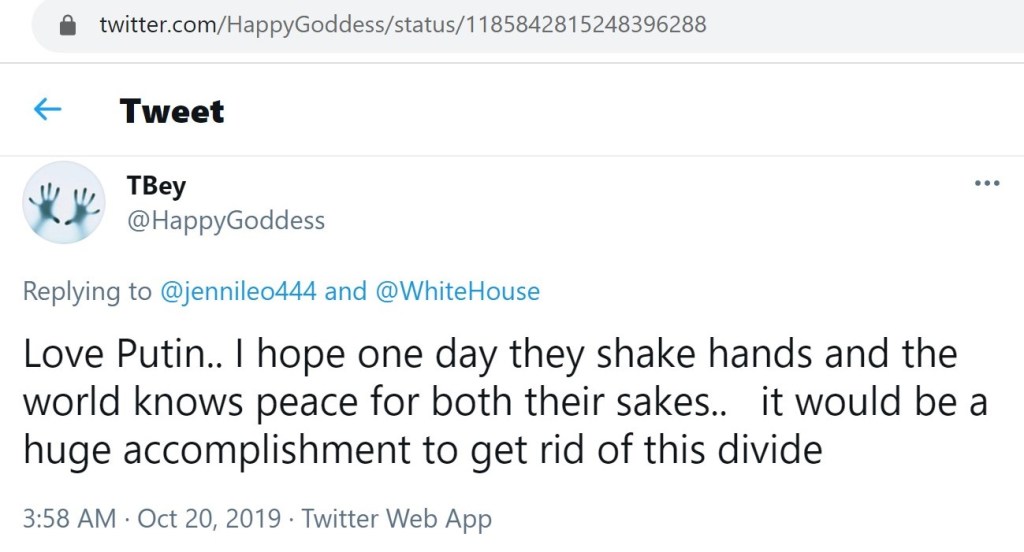
This operator also promoted the Kremlin’s position on Syria and pushed smears about the White Helmets.
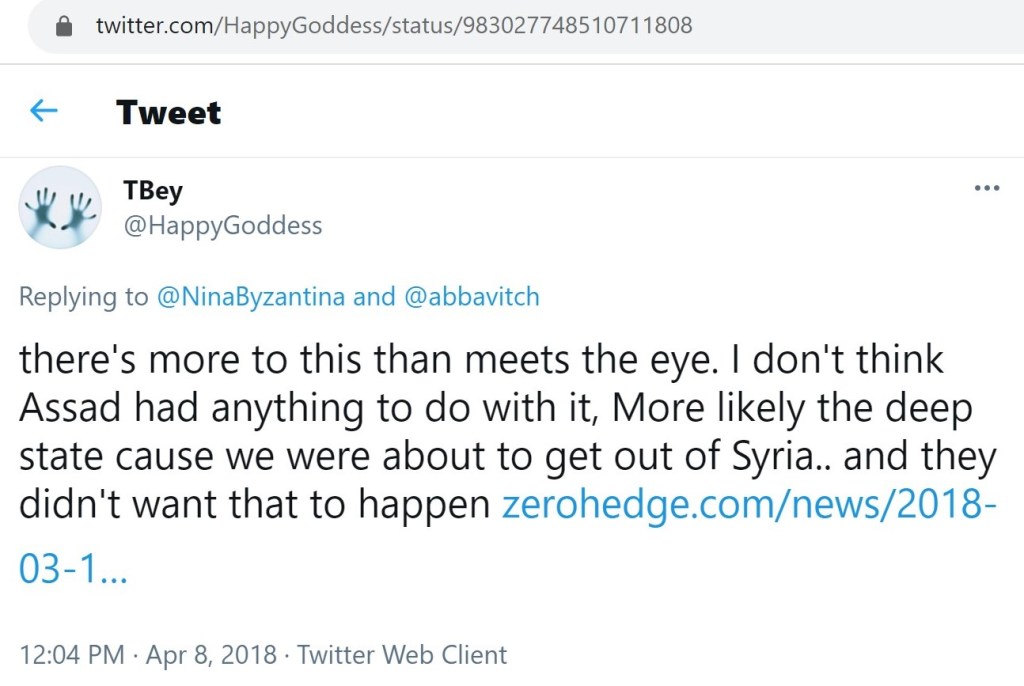

Recently, disinformation researchers have encountered the proliferation of a disingenuous narrative that insists there is no QAnon, only Q and the anons. @HappyGoddess pushed that narrative in February 2021.
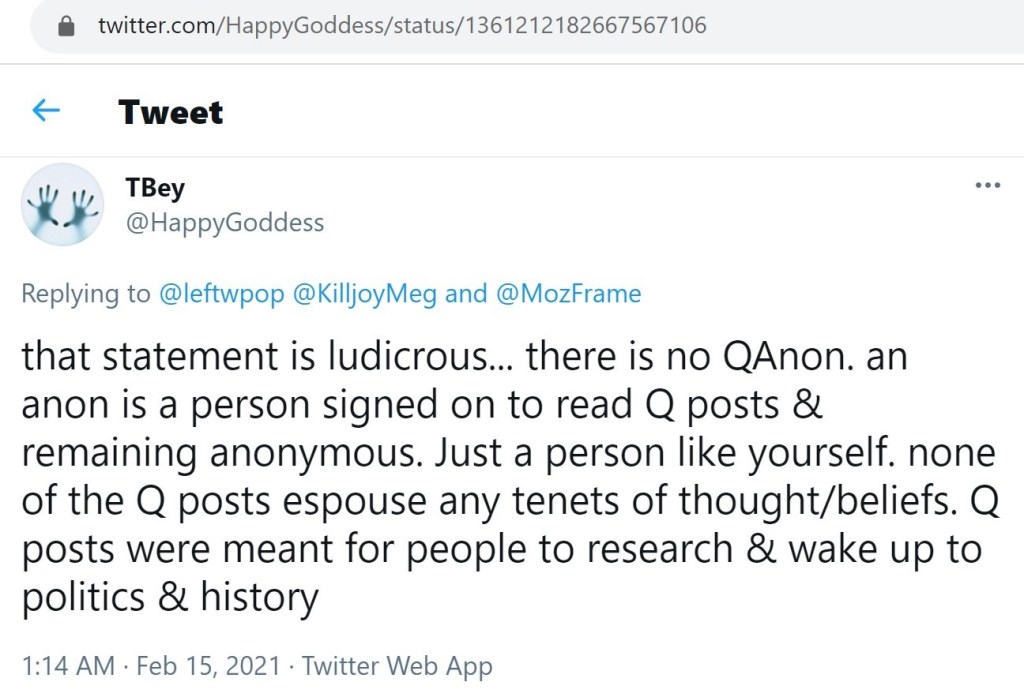
This narrative was also promoted by Q in October 2020. At the beginning of post #4881, Q wrote, “There is ‘Q’. 1 There are ‘Anons’. 2 There is no ‘Qanon’. 3.” A simple search of Q’s posts reveals quite a number of references to QAnon, to include Q posting links to online searches for QAnon in posts #3206 and #4103.
@noLongerAdem1
Note: The two screenshots above are of the same tweet. The URL preview obscured the date, necessitating a second screenshot.
Back in January 2021, I did a case study which focused on Twitter user @joeyyeo13. As fate would have it, @noLongerAdem1 didn’t just promote one of the aforementioned eBooks. This Twitter account also posted some content that was virtually identical to content that was posted by @joeyyeo13. I will be highlighting a few examples below.
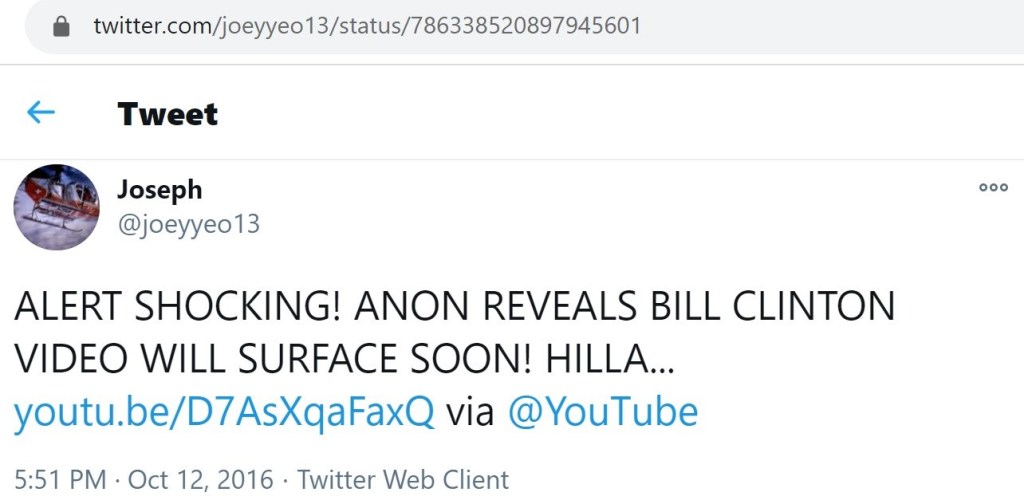

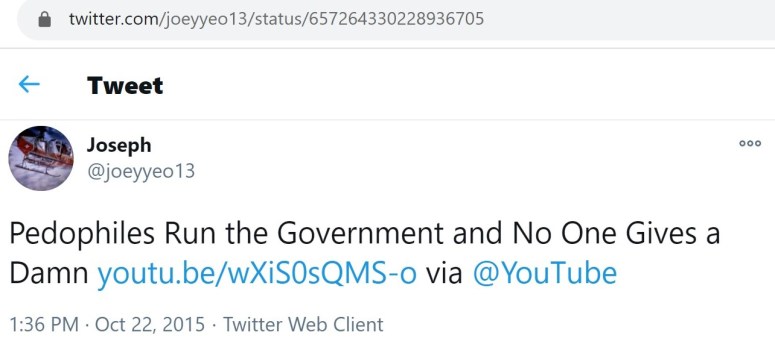
Like @joeyyeo13 and @HappyGoddess, this account used their platform to push pro-Putin content. Those who have read my other studies will find this content to be very familiar.
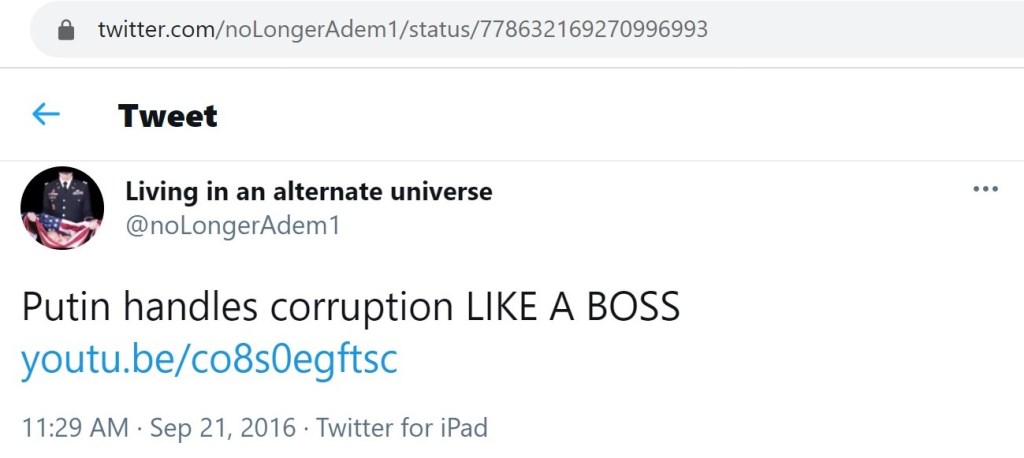
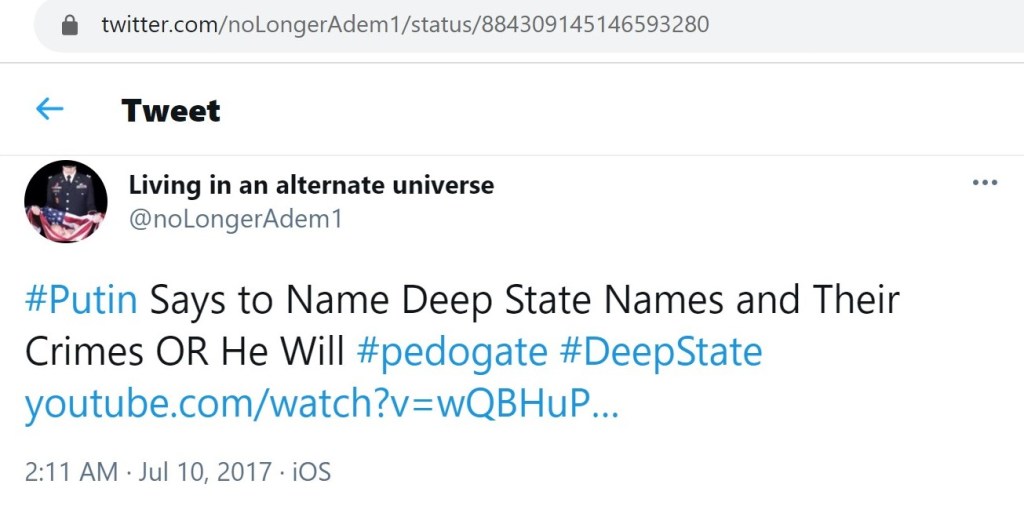
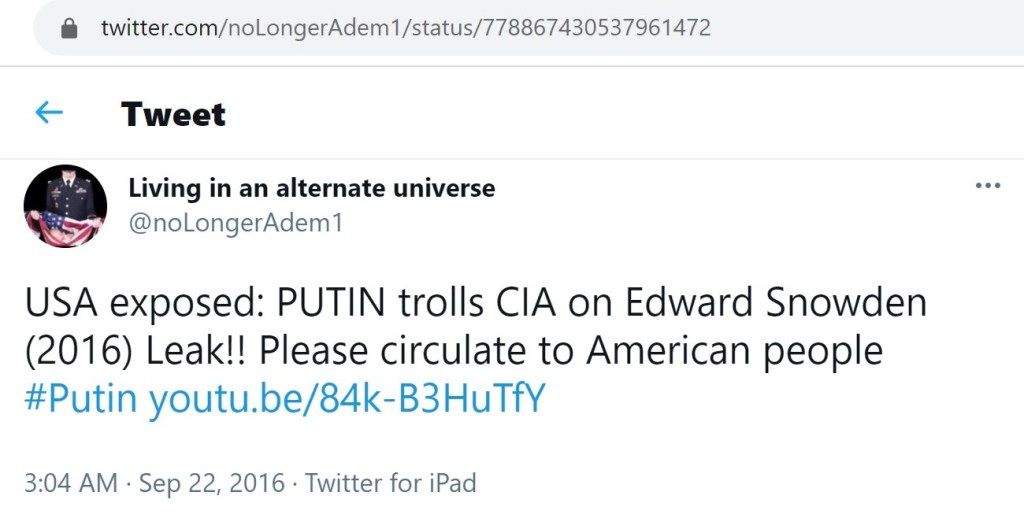
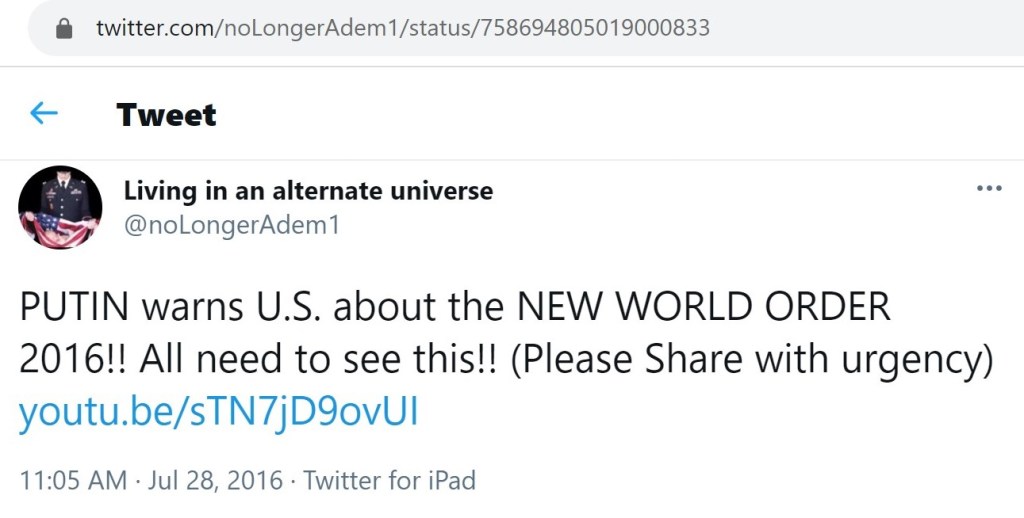

Some of the promoted links no longer work. However, the first link on the left goes to a reupload of a video that was originally broadcast by Channel One Russia. And while the YouTube channel which propagated the false claim about an international arrest warrant for Soros has since been suspended, the underlying message still remains. This same message, nearly word for word, was amplified by the previously uncovered Russian trolls.

To some, the overall point of this messaging may seem subtle. To others, it might seem overt. First, the Russian trolls generated or amplified claims which cast Soros as a puppet master, an international criminal, Satanic, etc. Then they occasionally push content which casts Putin and/or his allies as the solution to the fabricated Soros problem. It is a simple narrative of ‘good’ versus ‘evil.’ It doesn’t matter that no international arrest warrant for Soros exists. The underlying suggestion is what matters.
Notably, the aforementioned arrest warrant fact-check traced some of this claim back to the Kremlin-proxy site Veterans Today. As I recently covered on Twitter, Q cited a Veterans Today headline verbatim. It read, “Vladimir Putin: The New World Order Worships Satan.” Unsurprisingly, Putin didn’t actually say that phrase.
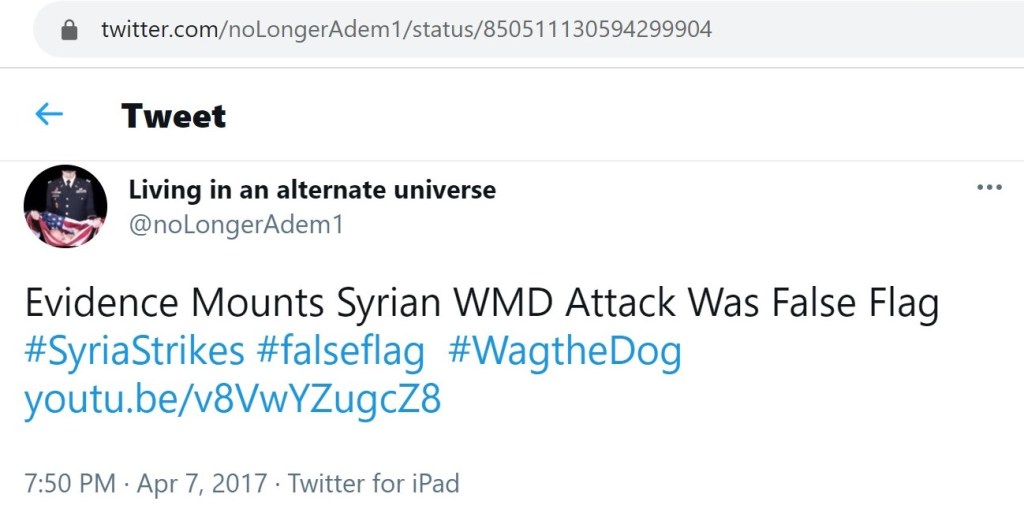
@noLongerAdem1 also advanced one of the Kremlin’s preferred narratives about Assad’s use of chemical weapons.

This user also pushed Guccifer 2.0 and DC Leaks and then spread false claims about Seth Rich.
This account also pushed a familiar narrative about Soros and/or the Clintons rigging the 2016 election. Similar narratives would reemerge online in 2020. This may seem as though this is about Hillary and Soros. That is certainly how it reads. However, if Hillary Clinton and George Soros had never existed, this messaging would be pushed, nevertheless. It would simply be reformulated with different individuals being falsely accused. When Russian trolls push claims of election rigging, the primary aim is to undermine confidence in Western democracy.

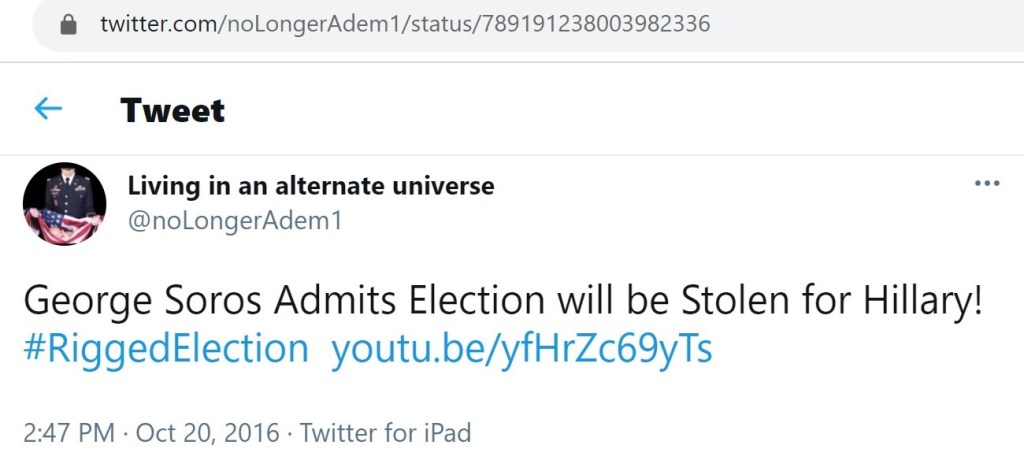
Pushing such claims in English is not just about attempting to influence an English-speaking audience. This English content can also be highlighted by Russian outlets in an underhanded way to influence a Russian audience. The message is, essentially, “See. We are not just saying Western democracy has many problems, such as rigged elections. They are saying it.”
The next tweet is not a duplicate of the highlighted tweet from @joeyyeo13, yet it is still very illuminating.
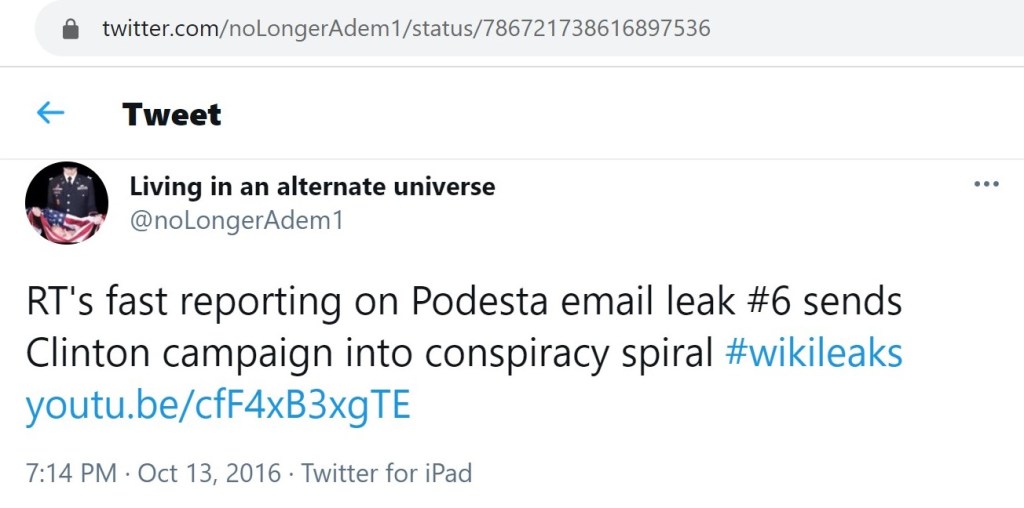
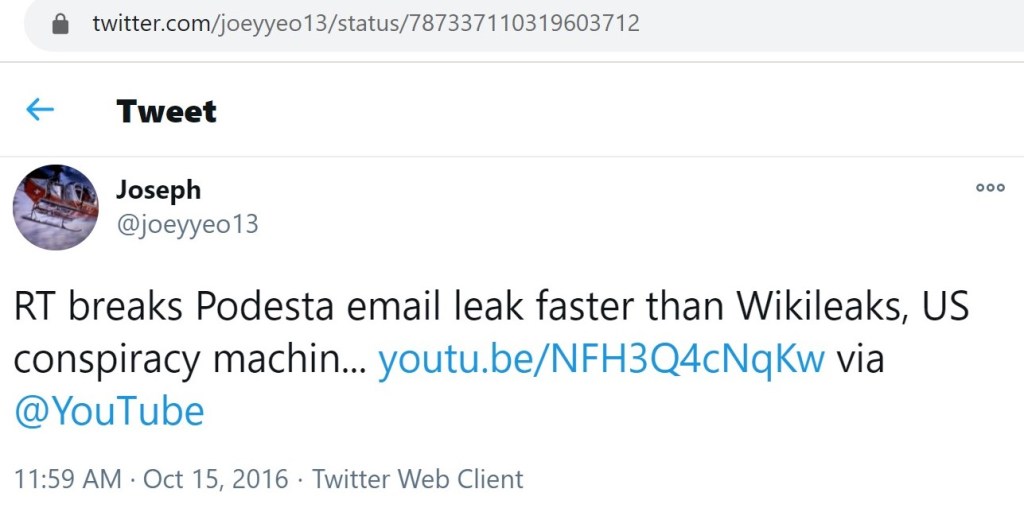
I covered the latter @joeyyeo13 tweet in more detail in that earlier case study. To summarize, when US media outlets noticed that Russia Today published a new Podesta leak before Wikileaks announced it, both Wikileaks and Russia Today offered a very dubious explanation. What I learned from @noLongerAdem1’s tweet is that RT published more than one video attempting to explain it away. @joeyyeo13 linked to one, while @noLongerAdem1 linked to the other.
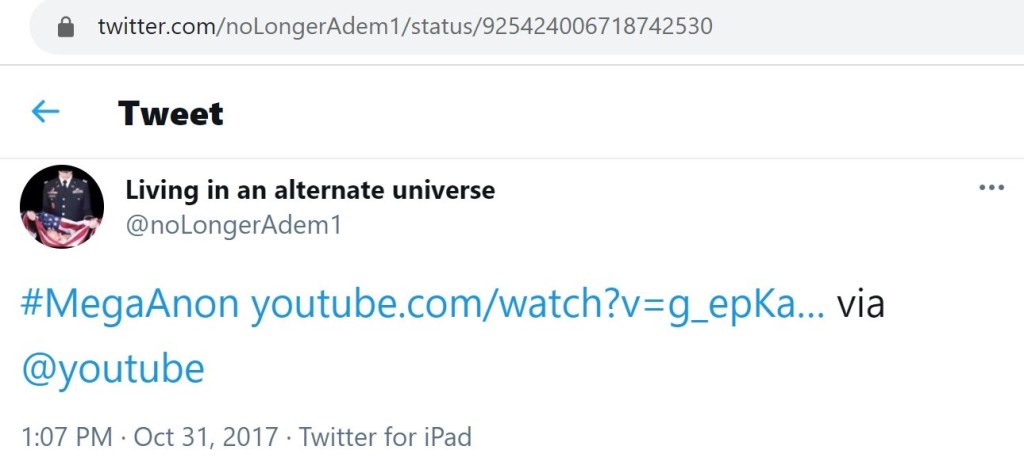
This account was also a very early pusher of ‘Q Clearance Patriot’ content and had also pushed MegaAnon content.
@SoulOnJourney11
The only Twitter account I found which directly linked to the Trumpenstein eBook was @SoulOnJourney11. This account also tweeted a link to the modified Wizard of Oz eBook and to the Hillary Clinton in Wonderland eBook.
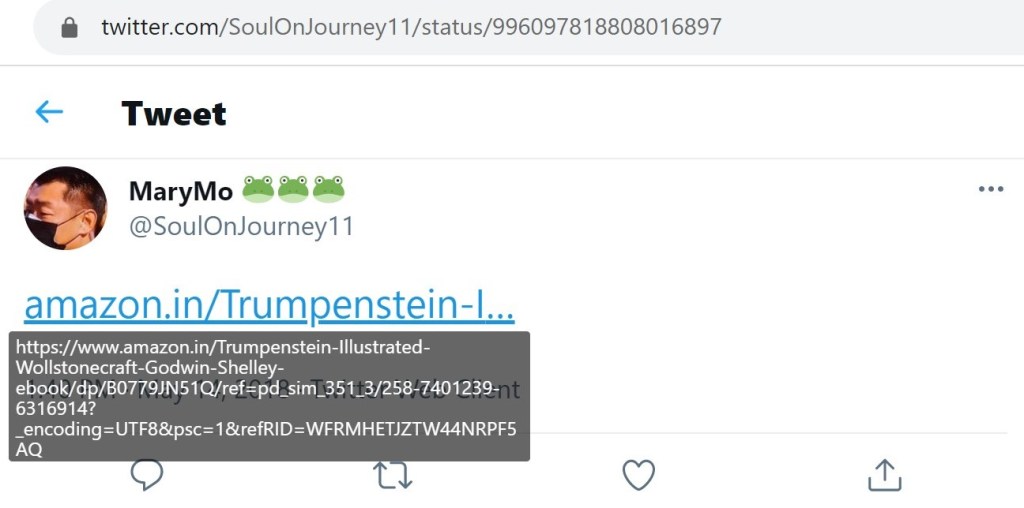
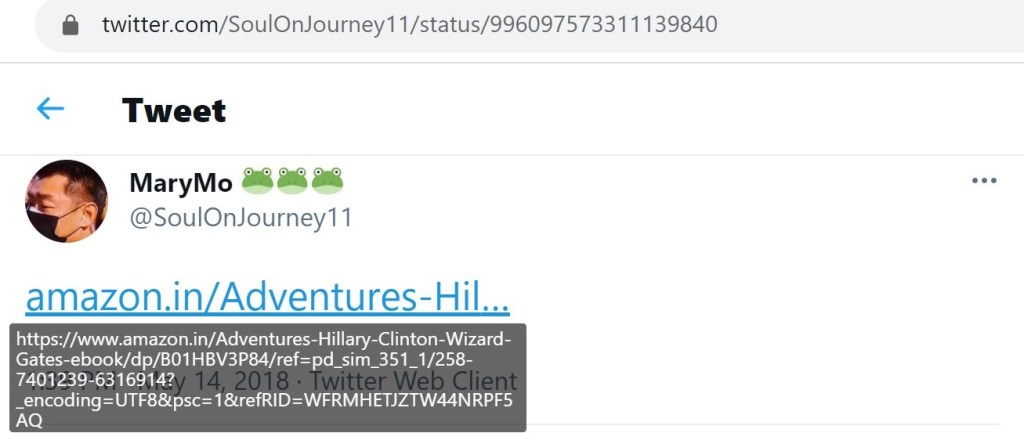
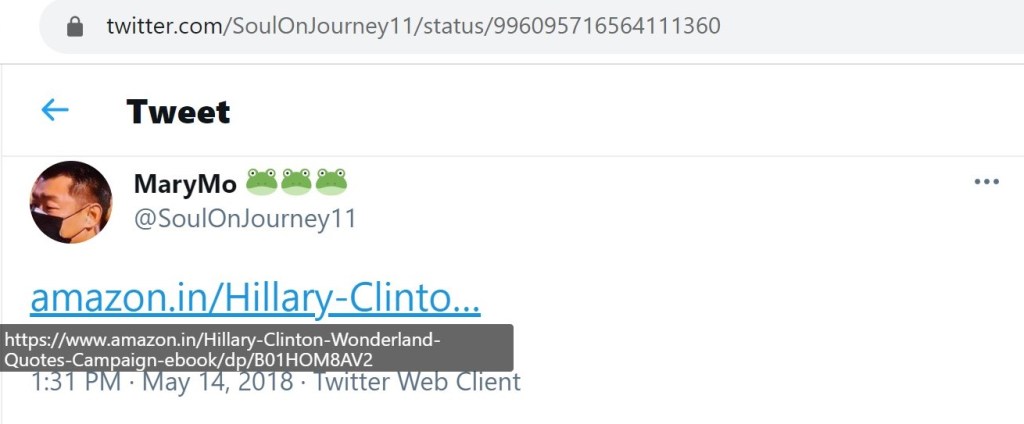
Note: The first two screenshots on the right are duplicates of the tweets to the left.
The following content is much like what we’ve reviewed with the prior Twitter accounts. At a certain point, reviewing these accounts ends up seeming very redundant. This is the primary reason I opt to do case studies, because there’s quite a lot of overlap between such accounts.
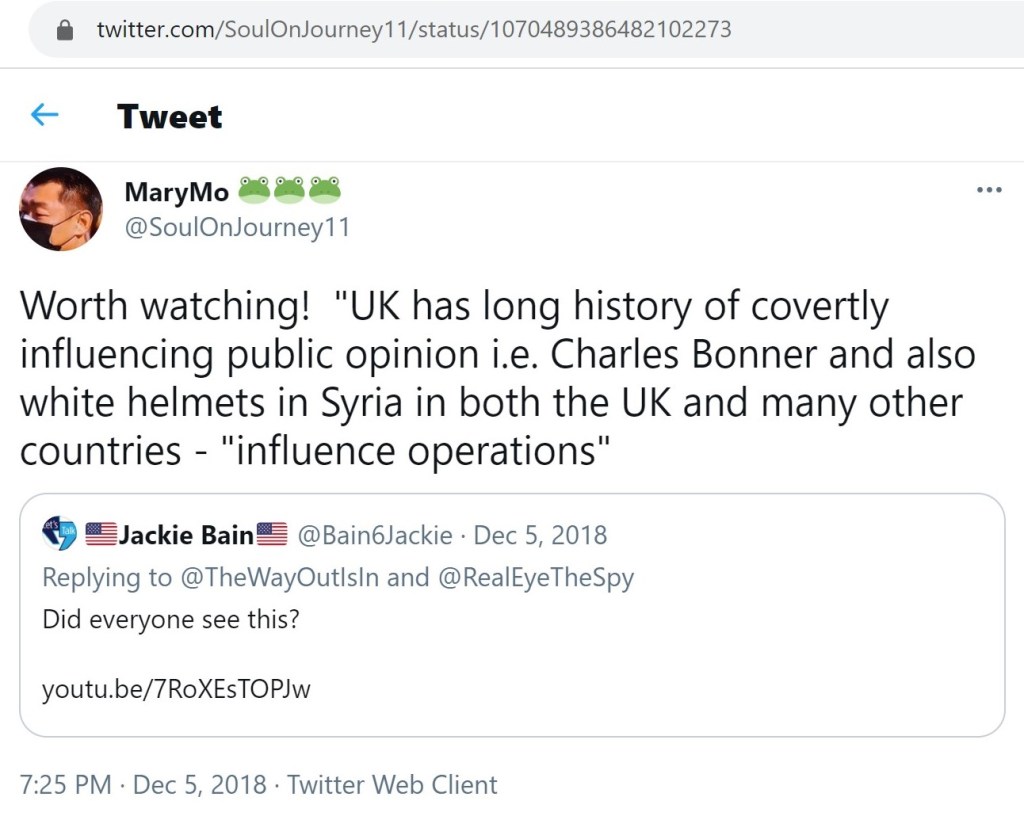
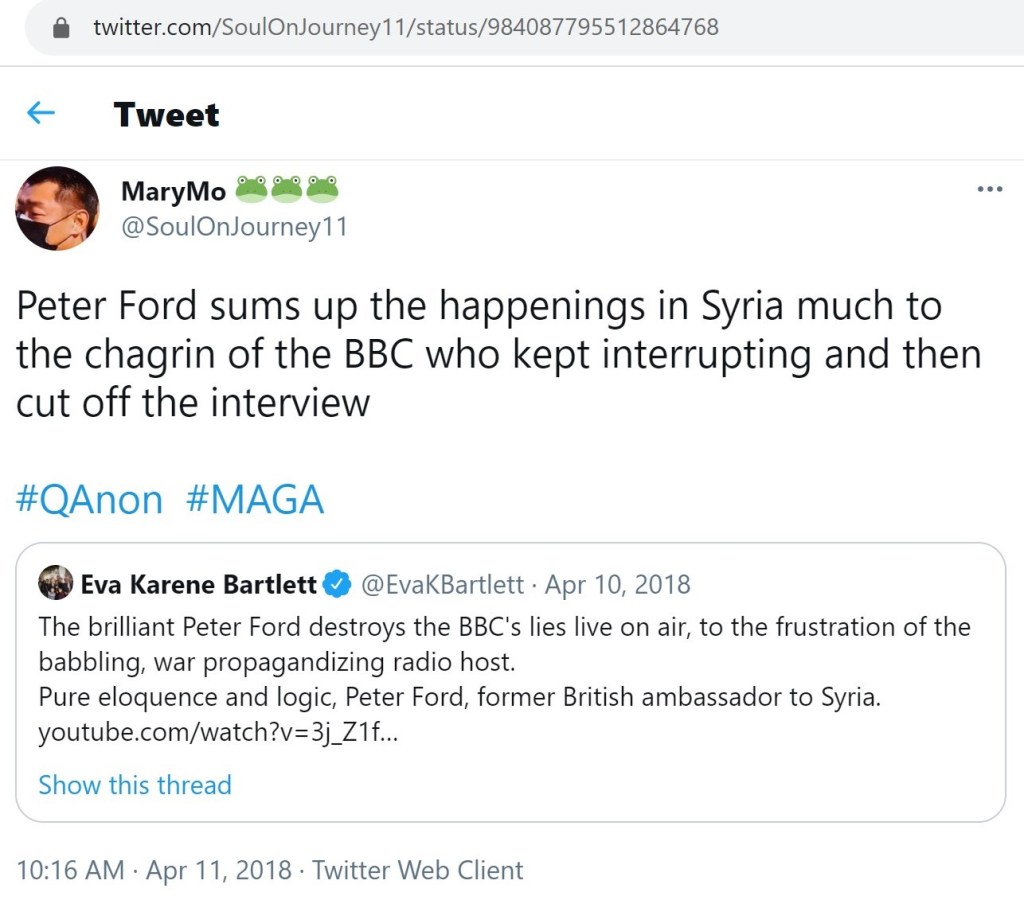
The first tweet from December 2018 links to a Russia Today video on YouTube. I highly doubt I need to go into detail about the April 2018 quote tweet. Most readers surely know who Eva Bartlett is. For those who don’t, a brief search online should give you a decent overview, if you opt to do so.


The first time I saw the next image was via the Internet Research Agency archives. I believe I have previously highlighted it in a separate piece, or perhaps in a tweet.
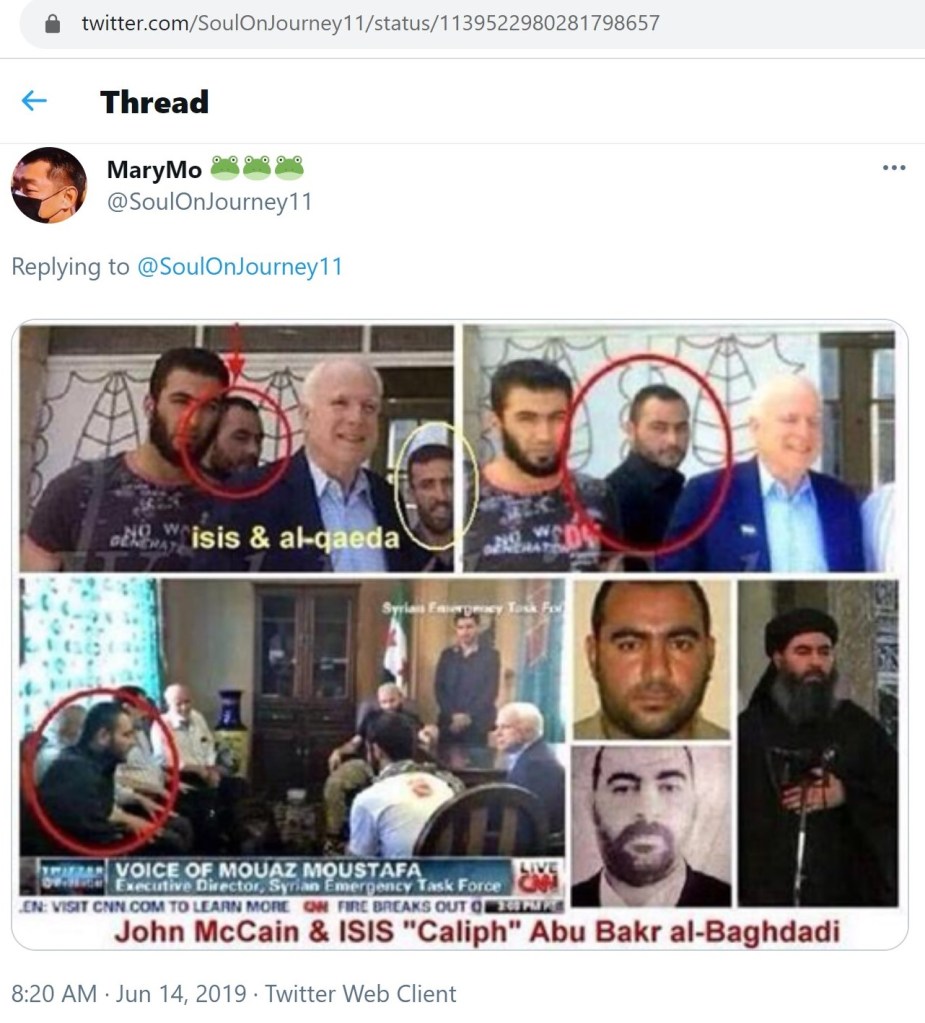
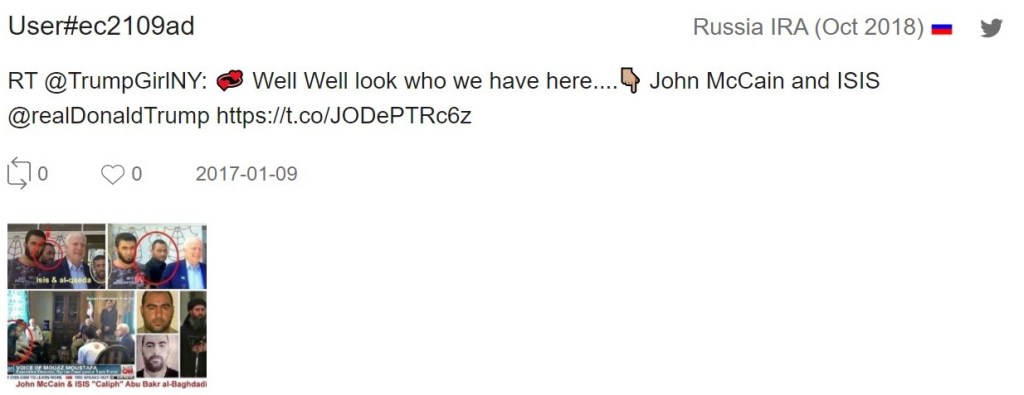
This account also interacted with and promoted content from Russia Today (RT).
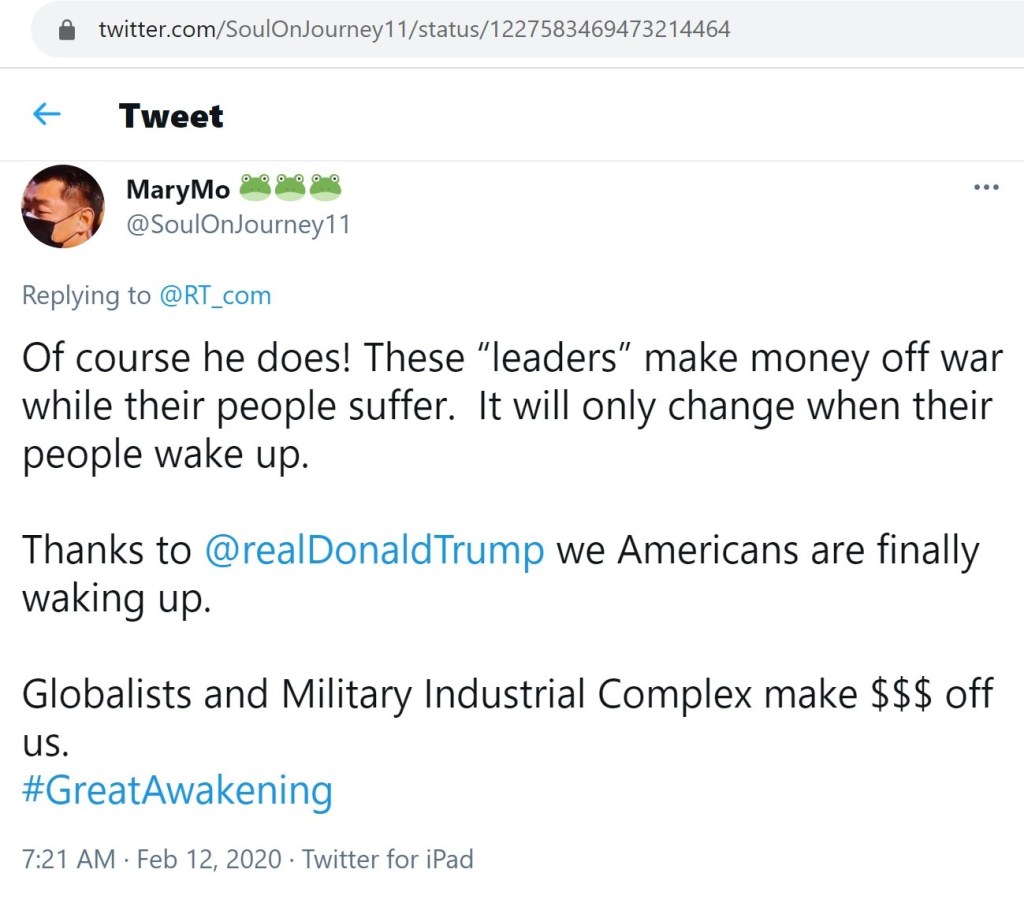
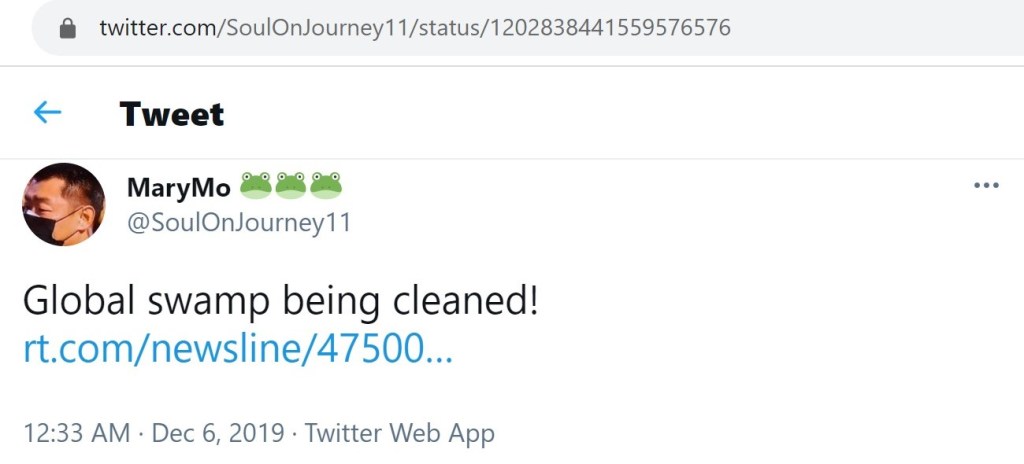
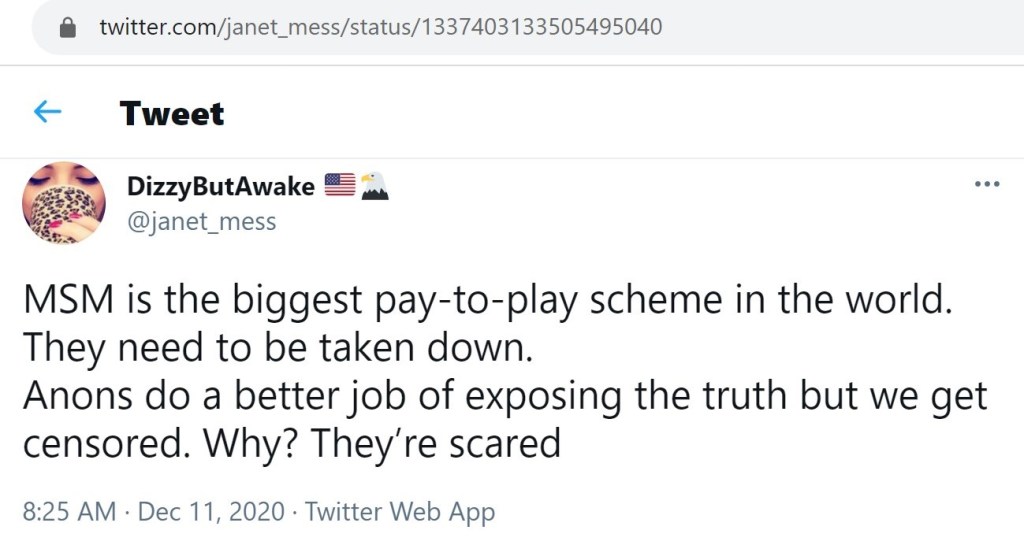
@janet_mess
The final Amazon link to be shared on Twitter was for the altered Through the Looking Glass eBook. Like the previous case, I was only able to track down a single instance of this link appearing on Twitter.
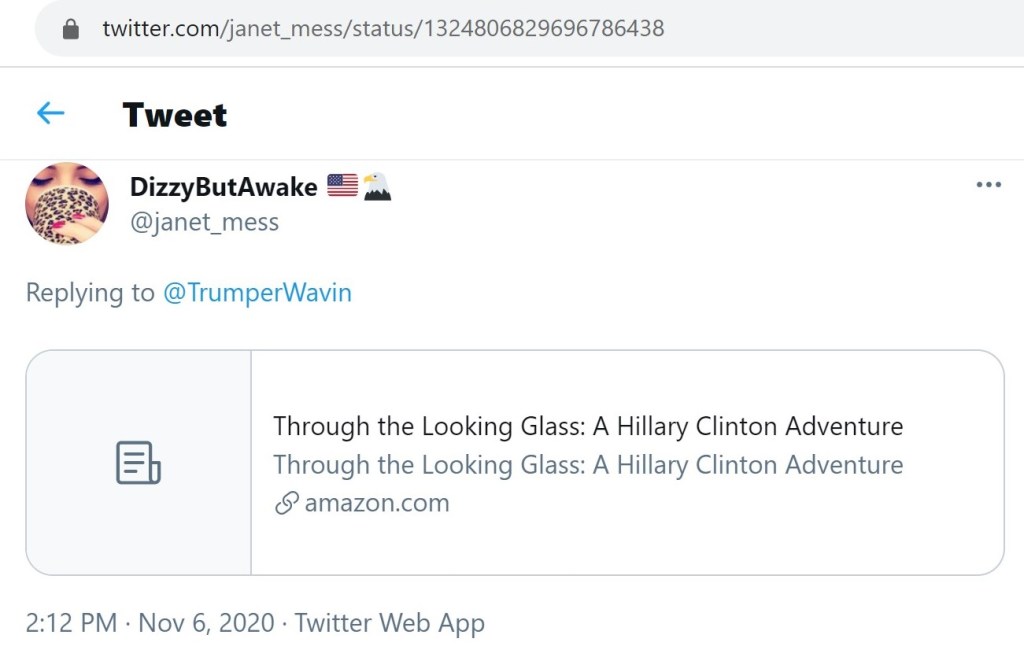
This account was created in January 2012. It became inactive in early 2016 and started posting again in mid-August 2020. There was a stark difference in activity when the account began posting in 2020. The evidence points to this account being abandoned by the original creator and then breached and taken over later.
Of the three examples below illustrating this account’s promotion of Q, the tweet dated November 5, 2020 is the most informative. The included screenshot of Q post #110 speaks to a couple of Q’s motives.
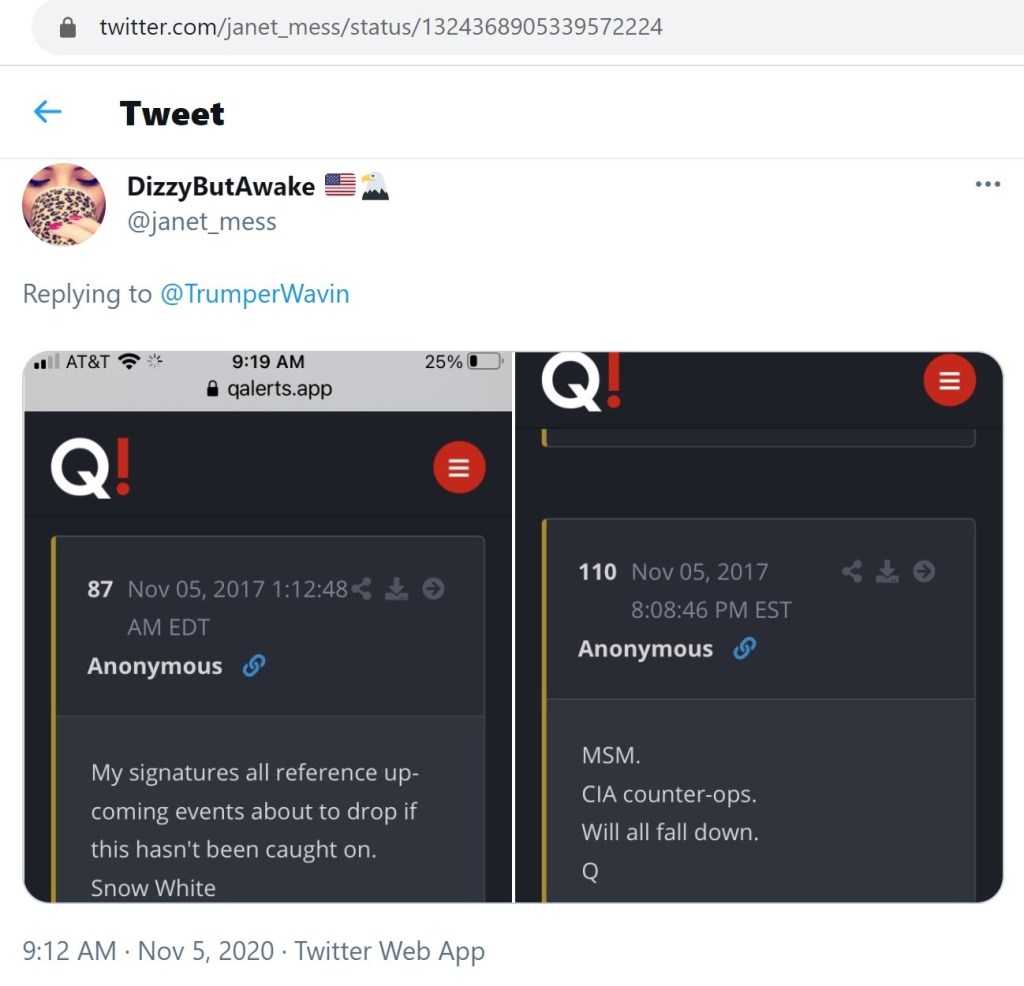
With each of these accounts and with Q, we find that not only do they seek to undermine the ‘MSM,’ but they also uncritically promote content from Russia Today and similar sites.

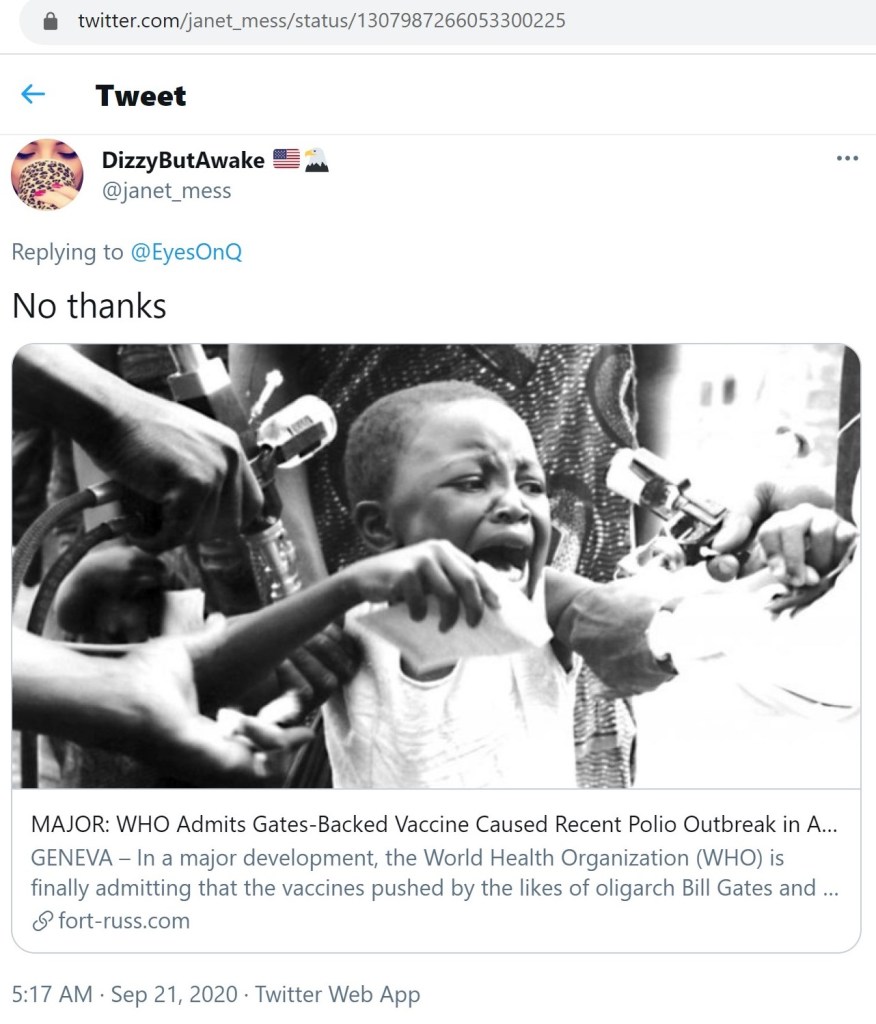
The Internet Research Agency trolls in Saint Petersburg and similar operations mean something slightly different when they refer to the ‘mainstream media.’ Although typically (but not always) left unsaid, what they mean is ‘Western mainstream media’ and ‘mainstream US media.’

The tweet on the left, in context, is a restating of the @noLongerAdem1 content we reviewed earlier.
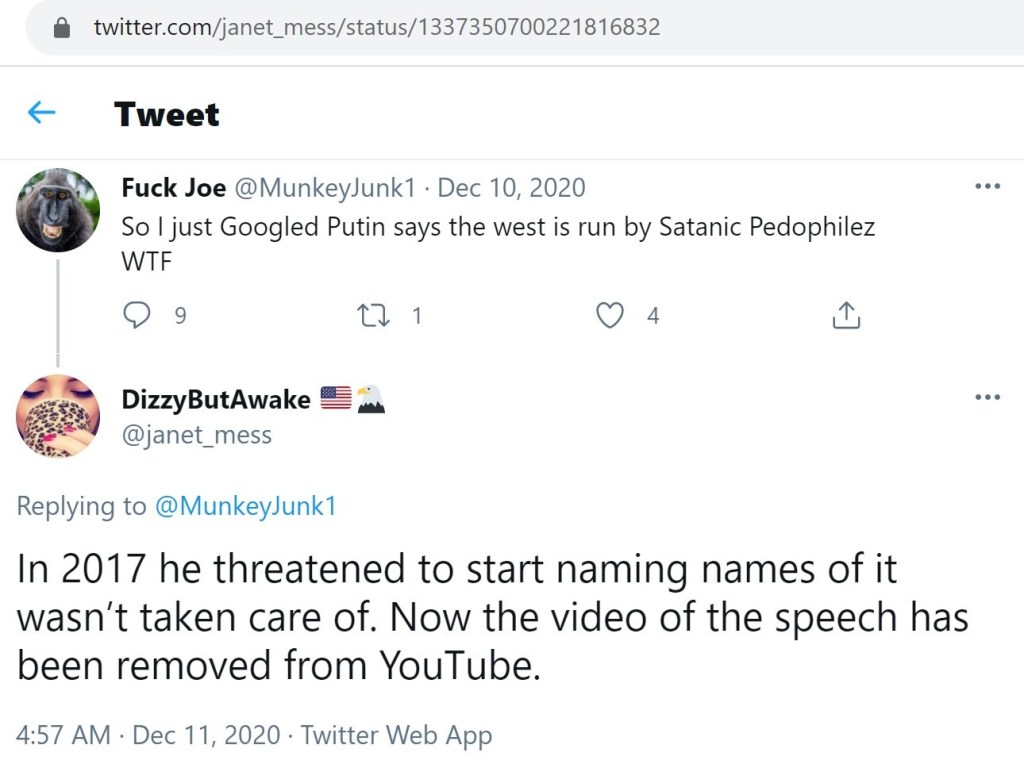
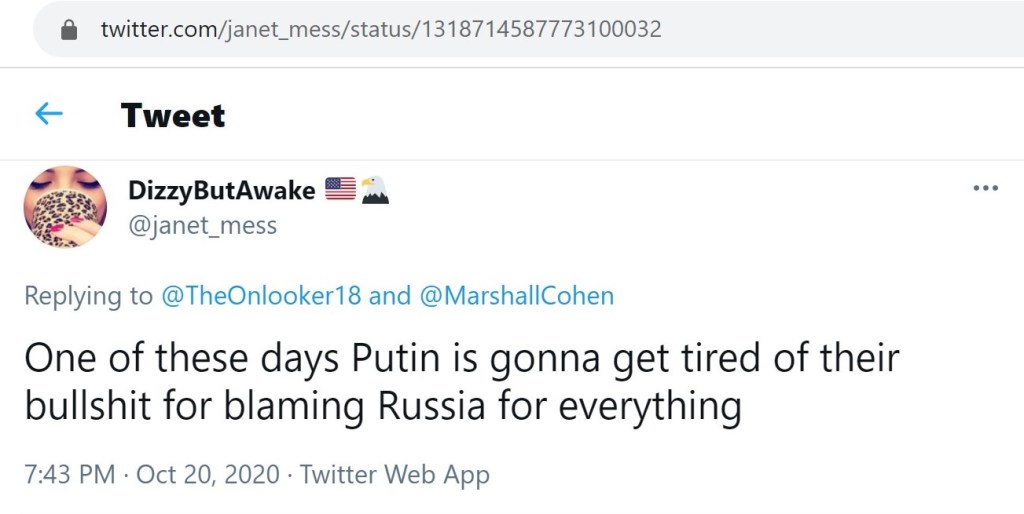
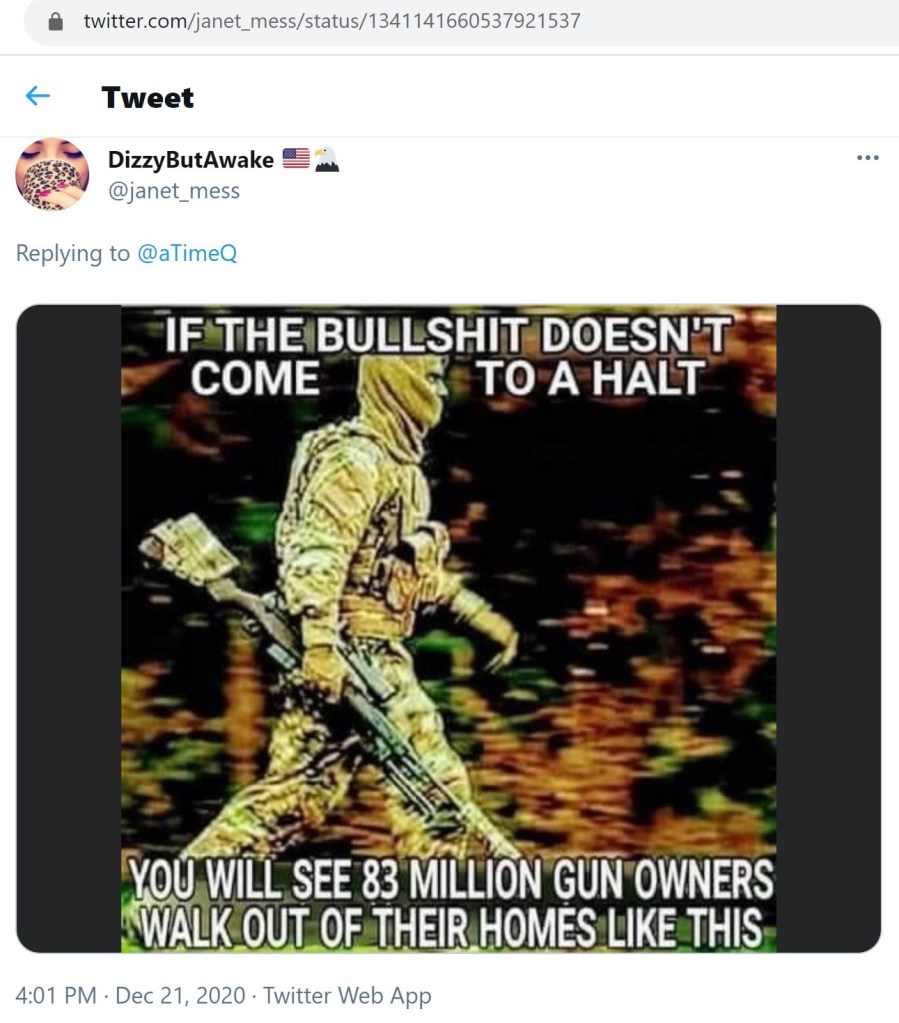
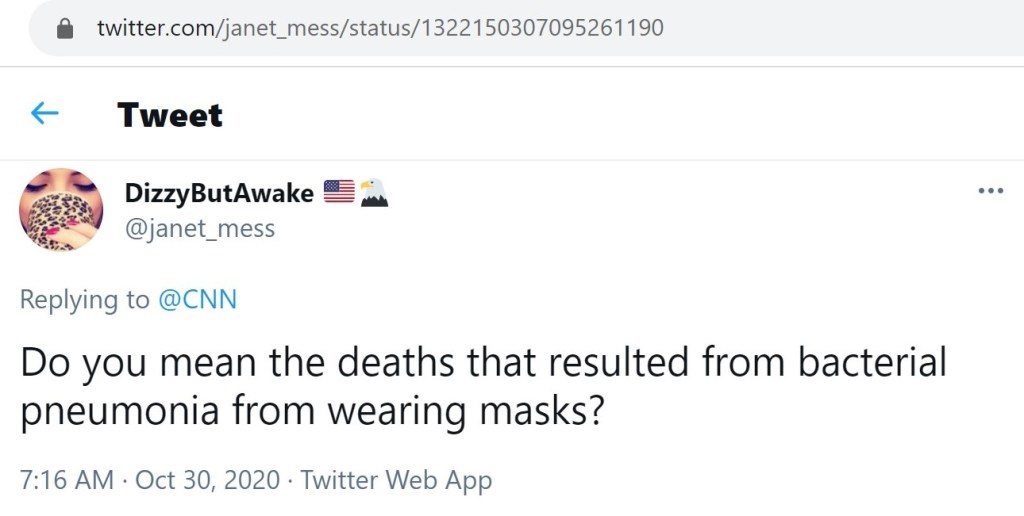
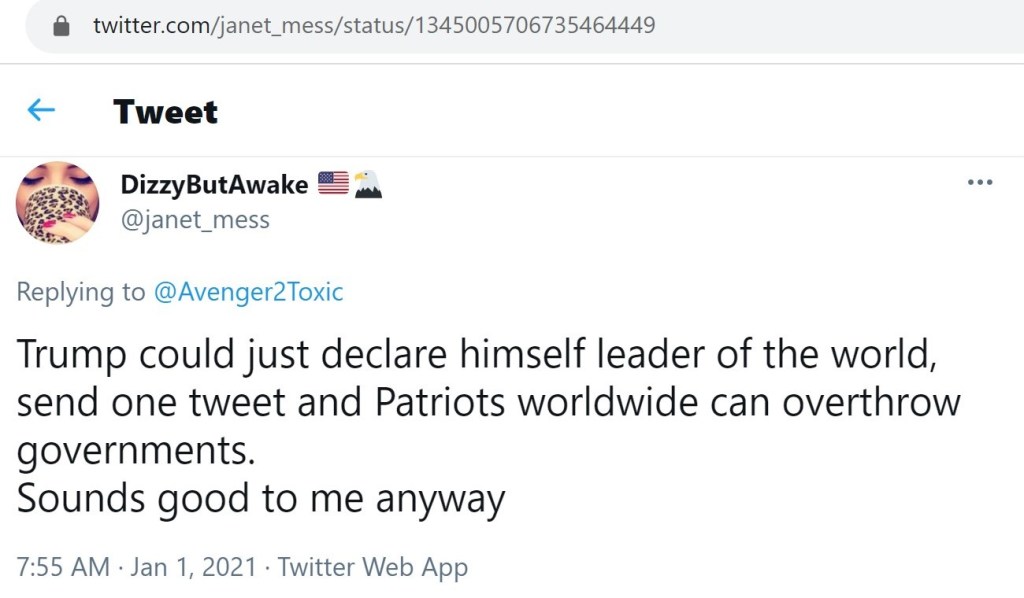
Finally, there were a few tweets that don’t quite require any further commentary to convey how concerning they are.